

认识Redis集群——Redis Cluster
发布于2020-11-19 20:49 阅读(1334) 评论(0) 点赞(2) 收藏(5)
前言
Redis集群分三种模式:主从模式、sentinel模式、Redis Cluster。之前没有好好的全面理解Redis集群,特别是Redis Cluster,以为这就是redis集群的英文表达啊,故写本篇博文来尽可能全面加深理解Redis Cluster。主要参考资料《Redis设计与实现》,主要是PDF电子版,有需要的朋友评论或者私聊!
一、Redis Cluster简单概述
1. Redis Cluster特点
- 多主多从,去中心化:从节点作为备用,复制主节点,不做读写操作,不提供服务
- 不支持处理多个key:因为数据分散在多个节点,在数据量大高并发的情况下会影响性能;
- 支持动态扩容节点:这是我认为算是Rerdis Cluster最大的优点之一;
- 节点之间相互通信,相互选举,不再依赖sentinel:准确来说是主节点之间相互“监督”,保证及时故障转移
2. Redis Cluster与其它集群模式的区别
- 相比较sentinel模式,多个master节点保证主要业务(比如master节点主要负责写)稳定性,不需要搭建多个sentinel实例监控一个master节点;
- 相比较一主多从的模式,不需要手动切换,具有自我故障检测,故障转移的特点;
- 相比较其他两个模式而言,对数据进行分片(sharding),不同节点存储的数据是不一样的;
- 从某种程度上来说,Sentinel模式主要针对高可用(HA),而Cluster模式是不仅针对大数据量,高并发,同时也支持HA。
以上都是一些查看资料后个人的见解,其中不足或者不完善的地方欢迎各位大佬指出!
二、Redis Cluster如何集群实现?
1.Redis Cluster是如何将数据分片的?----哈希槽Slot
(1)哈希槽介绍
Redis集群使用一种称作一致性哈希的复合分区形式(组合了哈希分区和列表分袂的特征来计算键的归属实例),键的CRC16哈希值被称为哈希槽。比如对于三个Redis节点,哈希槽的分配方式如下:
第一个节点拥有0-5500哈希槽
第二节点拥有5501-11000哈希槽
第三节点拥有剩余的11001-16384哈希槽
一个键的对应的哈希槽通过计算键的CRC16 哈希值,然后对16384进行取模得到:HASH_SLOT=CRC16(key) modulo 16383,Redis提供了CLUSTER KEYSLOT命令来执行哈希槽的计算:

实践举例说明:当我们创建一个Cluster时,系统会默认给我们分好片(你选择接受系统分配的配置),比如现在有7000-7005六个节点,其中我们分配3个主节点(7000-7002),3个从节点(7003-7005):
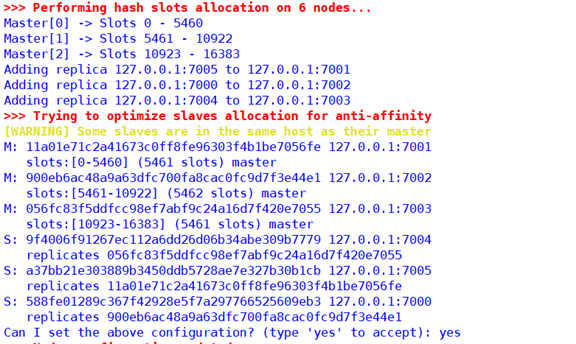
其中slots系统已经指派给了:Master[1]节点拥有0-5500哈希槽、Master[2]节点拥有5501-11000哈希槽、Master[3]节点拥有剩余的11001-16384哈希槽。
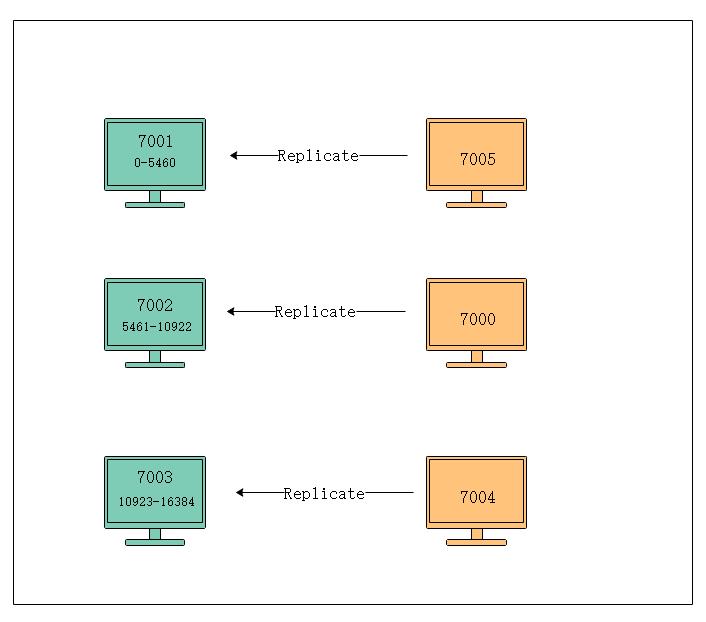
2. 在集群中执行命令
(1)在集群中执行set/get命令
对数据库中的16384个槽都进行了指派后,集群就会进入上线状态,这是客户端就可以向集群中的节点发送数据命令,需要进行计算出命令要处理的键是属于哪个槽的,并检查是否指派给了自己。
如果键所在的槽正好指派当前节点,那么节点直接执行这个命令:

如果键所在的槽并没有指派给当前节点,那么节点会向客户端返回一个MOVED错误(集群模式下,MOVED错误是回被隐藏的,不会显示的,而是直接显示Redirected,注:MOVED错误接下来会详细介绍),指引客户端转向(redirect)至正确的节点,并再次发送之前想要执行的命令。
比如:msg这个可以就被重定向指派到了7002节点上,

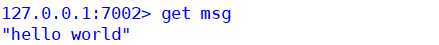
(2)执行加入集群命令(这周内补充完,先mark下使文章结构清晰)
3. 节点数据库的实现
集群节点保存键值对以及键值对过期时间的处理方式与Redis单机模式是一样的,唯一不同就是节点只能使用0号数据库,而单机Redis服务器则没有限制。这其实是一个小细节,也是需要注意的!
4. 重新分片
- Redis集群重新分片操作可以将任意数量的已经指派给某个节点的槽改为指派给另一个节点(目标节点),并且相关槽所属的键值对也会从源节点被移动到目标节点上。
- 重新分片操作可以在线进行,在重新分片过程中,集群不需要下线,并且源节点和目标节点都可以继续处理命令请求。
- Redis集群的重新分片操作是由集群管理软件redis-trib负责执行的,Redis提供了进行重新分片所需要的所有命令,redis-trib则通过向源节点和目标节点发送命令来重新分片操作。
-----------------------这里还没有完全对相关命令实践,先mark一下,这周内补充完成(其实就是督促自己不断学习)-------------------------------
5. MOVED错误与ASK错误
(1)MOVED错误
上述在集群中执行:set/get命令时,提到过MOVED错误,MOVED的错误格式(实际上会被隐藏):
# 表示槽10086正由127.0.0.1,端口号为7002的节点负责。
MOVED 10086 127.0.0.1:7002
客户端与7000节点之间的通信如下:

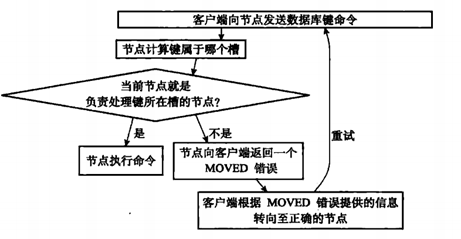
客户端根据MOVED错误,转向到7001节点再次发送SET命令:

一个集群客户端通常会与集群中的多个节点创建套接字连接,而所谓的节点转向实际上就是换一个套接字进行发送命令。具体的流程如下:
(2)ASK错误
在进行重新分片期间,源节点向目标节点迁移过程中,可能会出现这样一种情况:当客户端有操作键值对的有关的命令,同时该键值对正好属于被迁移槽。并且被迁移槽的部分键值对还驻留在source节点中,另外部分键已经保存在target节点中;则会进行下列动作:
- 如果能在source节点找到对应的key,那么直接执行client的命令;
- 如果找不到该key,那很有可能就在target中,此时source节点会向client发送一个ASK错误,引导client转向正在导入槽的target节点,并再次发送之前想要执行的命令。
举例说明:比如在源节点中一开始有key1-key3三个key,此时需要源节点需要向目标节点迁移,key2已经迁移完成,key3正在迁移,则会发生以下动作:
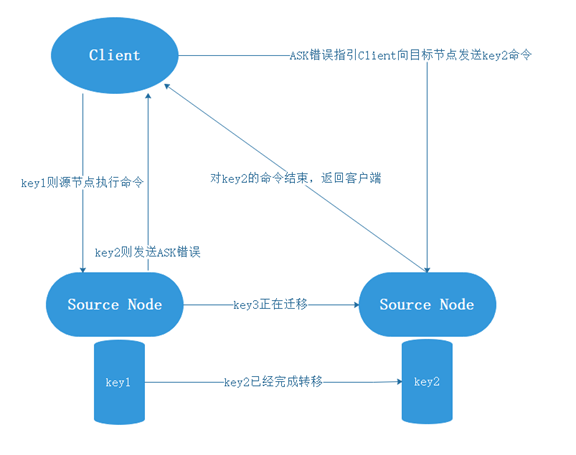
(7)ASK错误与MOVED错误的区别
按照参考书上定义其实就已经很明了,两者之间的区别
- MOVED错误表示槽的负责权已经从一个节点转移到另外的节点。
- ASK错误则是表示两个节点在迁移槽过程中对key处理的负责权。
三、Redis Cluser是如何保证HA的?
Redis Cluster保证高可用主要还是依靠:故障检测与故障转移两种策略,这其实很多分布式集群都能保证,但是针对Redis Cluster有一些细节需要好好学习并理解。
1、故障转移
举例说明:包含7000、7001、7002、7003四个主节点的集群,我们此时加入7004、7005两个节点,并当做7000的主节点的两个从节点。
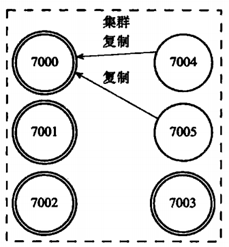
如果此时主节点7000下线(宕机),那么集群中仍然有几个主节点将在节点7000的两个从节点7004、7005中选择一个节点作为主节点,比如选择了7004则这个新节点将接管原来节点7000负责处理的槽,并继续处理客户端发送的请求,而7005此时作为7004的从节点。
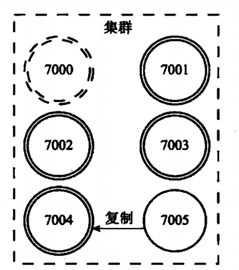
如果下线的7000节点,又重新上线的话,那它将作为节点7004的从节点。
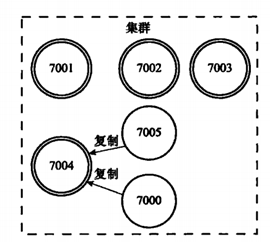
(1)设置从节点
命令:CLUSTER REPLICATE <node_id>,可以让接受命令的节点成为node_id所指定的从节点,并开始对主节点进行复制;比如根据之前实际操作的例子,我启动一个7006的节点,然后让它成为主节点7002的从节点。
在此之前的集群情况是这样的:

一个节点成为从节点以后,开始复制某个主节点这一信息会通过消息发送给集群中的其他节点,最终集群中所有节点都会知道某个从节点正在复制某个主节点。
-----------------------这里还没有完全对相关命令实践,先mark一下,这周内补充完成(其实就是督促自己不断学习)-------------------------------
(2)故障转移具体流程:
当一个从节点发现自己正在复制的主节点下线时,从节点将开始对下线主节点进行故障转移:
1) 在该下线主节点的所有从节点中,选择一个做主节点
2) 被选中的从节点会执行SLAVEOF no one命令,成为新的主节点;
3) 新的主节点会撤销对所有对已下线主节点的槽指派,并将这些槽全部派给自己。
4) 新的主节点向集群广播一条PONG消息,让其他节点知道“我已经变成主节点了,并且我会接管已下线节点负责的处理的槽”;
5) 新主节点开始接收和自己负责处理的槽有关的命令请求,故障转移完成。
(3)选举新节点
1)集群配置纪元是一个自增计数器,它的初始值为0;
2)当集群里的某个节点开始一次故障转移时,集群配置纪元的值会被增加1
3)对于每个配置纪元,集群里的每个负责处理槽的主节点都有一次投票的机会,而第一个向主节点要求投票的从节点将获得主节点的投票。
4)当从节点发现自己正在复制的主节点进入已下线状态时,从节点会向集群广播消息:要求所有收到这条消息、并且具有投票权的主节点向这个从节点投票。
5)如果一个主节点具有投票权,并且这个主节点尚未投票跟其它从节点,那么主节点将要求投票的从节点返回一条ACK消息,表示支持该从节点成为新的主节点。
6)每个主节点只有一次投票机会,所有有N个主节点的话,那么具有大于N/2+1张支持票的从节点只有一个。
7)如果在一个配置纪元里没有从节点能收集到足够多的支持票,那么集群进入一个新的配置纪元,并再次进行选举,直到选出新的主节点为止。
总结:这跟sentinel模式下的选举类似,两个都是基于Raft算法的领头选举方法来实现(不是很了解Raft算法,这里Mark下之后需要补充下Raft算法)。
2、故障检测
集群中每个节点都会定期地向集群中的其他节点发送PING消息,以此检测对方是否在线;如果接收PING消息的节点没有在规定的时间内,向发送PING消息的节点返回PONG消息,那么发送PING消息的节点就会将PING消息节点标记为疑似下线(possible fail,PFAIL)。
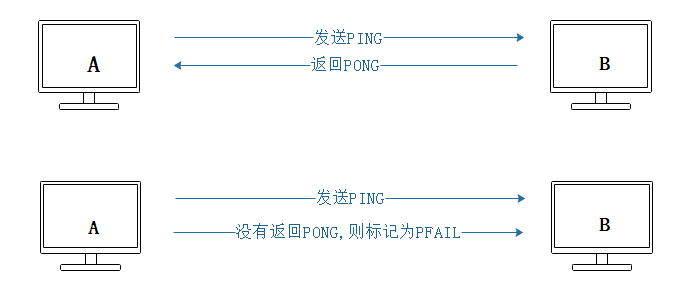
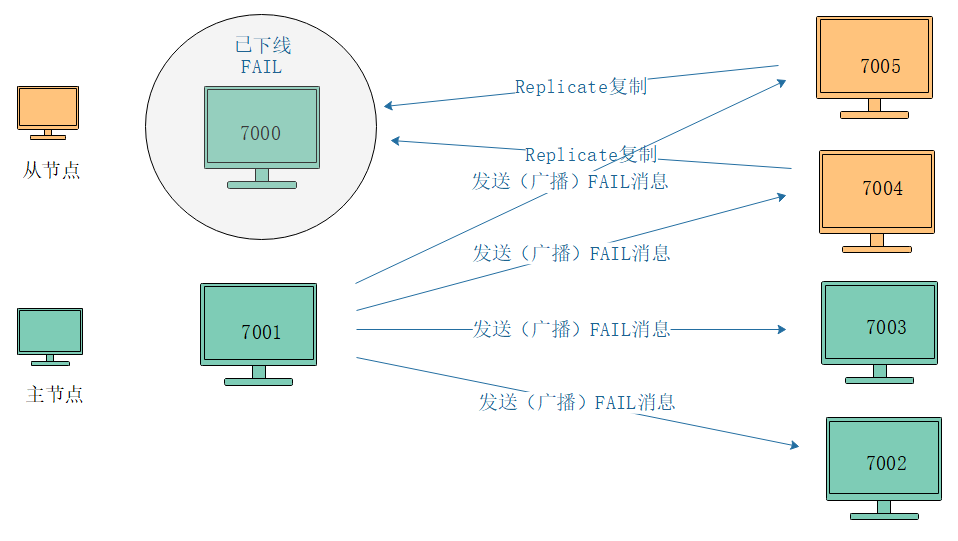
如果在集群中,超过半数以上负责处理槽的主节点都将某个节点X标记为PFAIL,则某个主节点就会将这个主节点X就会被标记为已下线(FAIL),并且广播到这条消息,这样其他所有的节点都会立即将主节点X标记为FAIL。
假设:
- Redis Cluster有四个主节点:7000-7003,两个从节点:7004与7005
- 此时7000已下线,并且主节点7001认为主节点7000进入PFAIL
- 同时主节点7002、7003也认为主节点7000进入下线状态
这样一来超过半数的主节点都认为7000节点FAIL,那么7001便会标记7000为FAIL状态,并向集群广播主节点7000已经FAIL消息。
原文链接:https://www.cnblogs.com/jian0110/p/14002555.html
所属网站分类: 技术文章 > 博客
作者:java之恋
链接:http://www.javaheidong.com/blog/article/1096/bf76671803505b7e9085/
来源:java黑洞网
任何形式的转载都请注明出处,如有侵权 一经发现 必将追究其法律责任
昵称:
评论内容:(最多支持255个字符)
---无人问津也好,技不如人也罢,你都要试着安静下来,去做自己该做的事,而不是让内心的烦躁、焦虑,坏掉你本来就不多的热情和定力