

大数据篇--Spark调优
发布于2021-05-29 22:50 阅读(1012) 评论(0) 点赞(19) 收藏(2)
一、算子的合理选择
pom.xml内容:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.huiq</groupId>
<artifactId>HuiqTest</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<encoding>UTF-8</encoding>
<scala.version>2.11.8</scala.version>
<spark.version>2.4.0</spark.version>
</properties>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<plugins>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
1.map和mappartition:
编写Scala程序模拟使用不同的算子将数据插入到数据中比较不同。
MapMappartitionApp:
package com.huiq.test
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable.ListBuffer
object MapMappartitionApp {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[2]")
.setAppName("MapMappartitionApp")
val sc = new SparkContext(sparkConf)
val students = new ListBuffer[String]()
for (i<-1 to 100) {
students += "stu: " + i
}
val stuRdd = sc.parallelize(students)
// 需要把students存储到数据库中去
myMap(stuRdd)
sc.stop()
}
def myMap(rdd: RDD[String]): Unit = {
rdd.map(x => {
val connection = DBUtils.getConnection()
println(connection + "------------>")
// TODO... 保存数据到数据库中
DBUtils.returnConnection(connection)
}).foreach(println)
}
}
运行程序我们会发现使用map算子有多少个元素就会创建多少个connection,这种性能肯定是不行的。
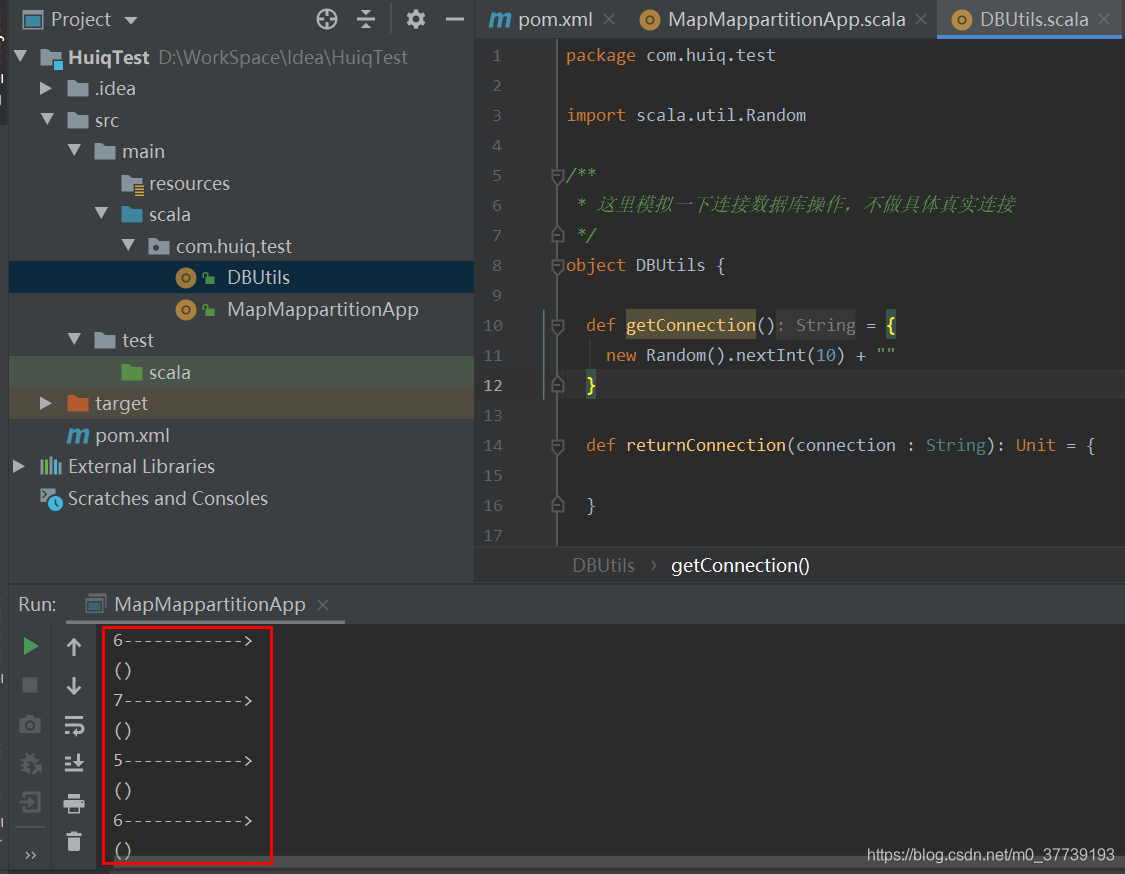
换成mapPartition再运行程序:
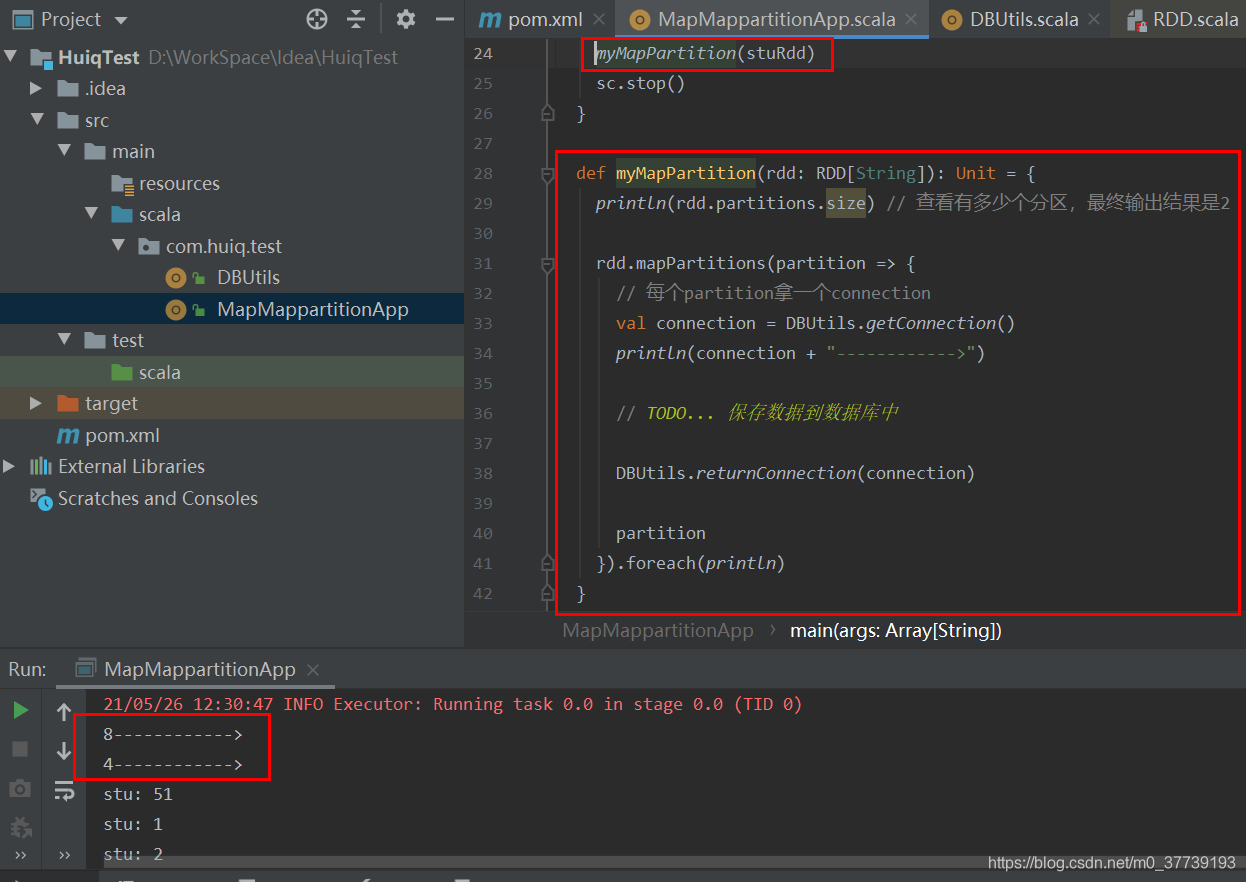
总结:map是对RDD中的每个元素作用上一个函数(你假设有个rdd有100个分区,每个分区里有1万个元素,你算一下整个过程会开启多少个connection?)。mapPartition是将函数作用到partition之上的(如果遇到要写数据到数据库,一定要选择该模式)。
思考:如果分区数量比较少导致一个分区中的数据量很大,这种场景下用mapPartition可能会有资源不够导致类似OOM的问题,遇到这种问题的时候可以手动调整partition的数量来解决,比如上面的代码可以设置成10个分区val stuRdd = sc.parallelize(students, 10)
2.foreach和foreachpartition:
package com.huiq.test
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable.ListBuffer
object ForeachForeachMappartitionApp {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[2]")
.setAppName("ForeachForeachMappartitionApp")
val sc = new SparkContext(sparkConf)
val students = new ListBuffer[String]()
for (i<-1 to 100) {
students += "stu: " + i
}
val stuRdd = sc.parallelize(students, 10)
// 需要把students存储到数据库中去
// myForeach(stuRdd)
myForeachPartition(stuRdd)
sc.stop()
}
def myForeach(rdd:RDD[String]): Unit = {
rdd.foreach(x => {
val connection = DBUtils.getConnection()
println(connection + "------------>")
// TODO... 保存数据到数据库中
DBUtils.returnConnection(connection)
})
}
def myForeachPartition(rdd:RDD[String]): Unit = {
rdd.foreachPartition(x => {
val connection = DBUtils.getConnection()
println(connection + "------------>")
// TODO... 保存数据到数据库中
DBUtils.returnConnection(connection)
})
}
}
总结:用法和map/mappartition是非常类似的,只不过是action和transformation的区别,写数据库一定要使用xxxxPartition。
3.reducebykey和groupbykey:
下面我们使用两种不同的方式去计算单词的个数[2]:
val words = Array("one", "two", "two", "three", "three", "three")
val wordPairsRDD = sc.parallelize(words).map(word => (word, 1))
val wordCountsWithReduce = wordPairsRDD.reduceByKey(_ + _)
val wordCountsWithGroup = wordPairsRDD.groupByKey().map(t => (t._1, t._2.sum))
上面得到的wordCountsWithReduce和wordCountsWithGroup是完全一样的,但是,它们的内部运算过程是不同的。
当采用reduceByKeyt时,Spark可以在每个分区移动数据之前将待输出数据与一个共用的key结合。借助下图可以理解在reduceByKey里究竟发生了什么。 注意在数据对被搬移前同一机器上同样的key是怎样被组合的(reduceByKey中的lamdba函数)。然后lamdba函数在每个区上被再次调用来将所有值reduce成一个最终结果。整个过程如下:
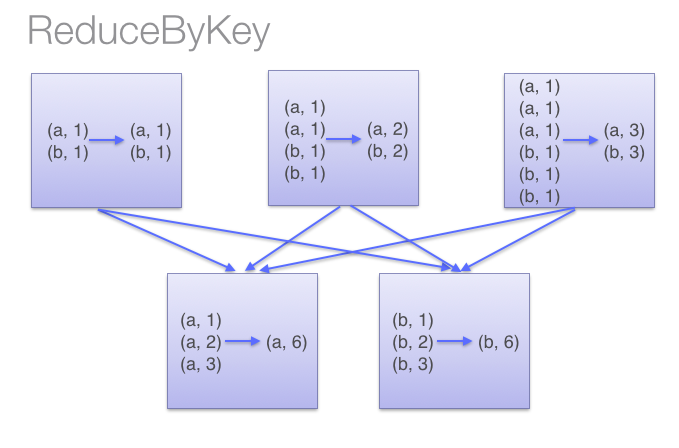
当采用groupByKey时,由于它不接收函数,spark只能先将所有的键值对(key-value pair)都移动,这样的后果是集群节点之间的开销很大。整个过程如下:
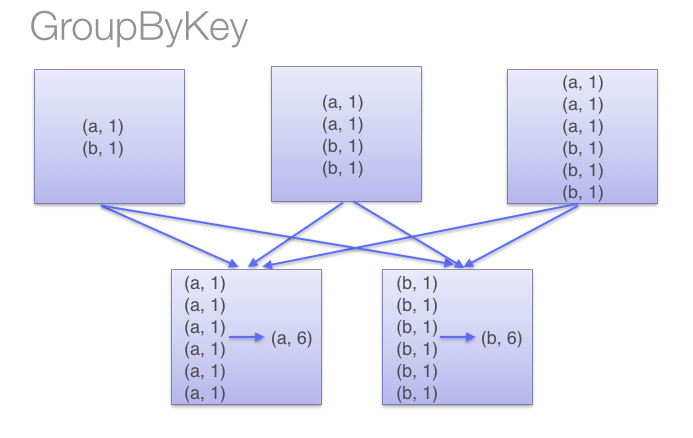
总结:reduceByKey会先在map端做一个本地的聚合,然后将聚合的数据进行shuffle操作;groupByKey将所有的key都经过了shuffle。所以在Spark中少用groupByKey而去选择reduceByKey。
4.collect:
查看源码中的定义:collect算子执行结果的数据全部放到一个数组中。
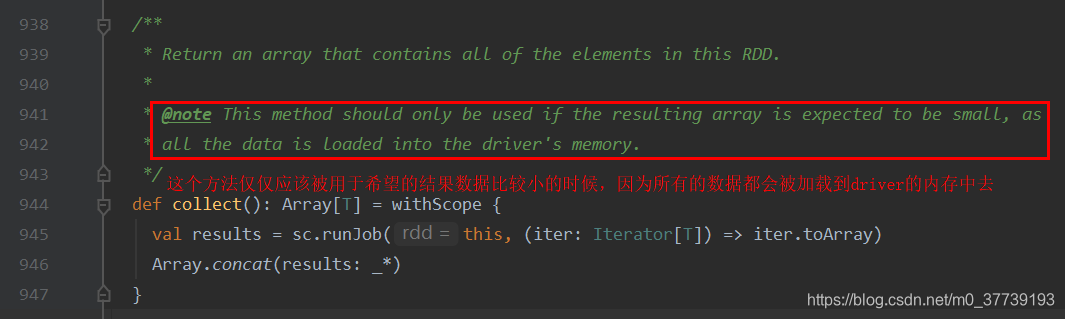
collect是Action操作里边的一个算子,这个方法可以将RDD类型的数据转化为数组,同时会从远程集群是拉取数据到driver端。最后将大量数据汇集到一个driver节点上,并且像这样val arr = data.collect(),将数据用数组存放,占用了jvm堆内存,可想而知,是有多么轻松就会内存溢出(OOM)。所以collect一定要慎用,你可能在测试环境测试不出来,一上生产环境全是坑,我们组内的小伙伴有的就这么干,结果上生产一堆问题。
如何规避:若需要遍历RDD中元素,大可不必使用collect,可以使用foreach语句;若需要打印RDD中元素,可用take语句,返回数据集前n个元素,data.take(1000).foreach(println),这点官方文档里有说明;若需要查看其中内容,可用saveAsTextFile方法。
补充:collectPartitions:同样属于Action的一种操作,同样也会将数据汇集到Driver节点上,与collect区别并不是很大,唯一的区别是:collectPartitions产生数据类型不同于collect,collect是将所有RDD汇集到一个数组里,而collectPartitions是将各个分区内所有元素存储到一个数组里,再将这些数组汇集到driver端产生一个数组;collect产生一维数组,而collectPartitions产生二维数组。
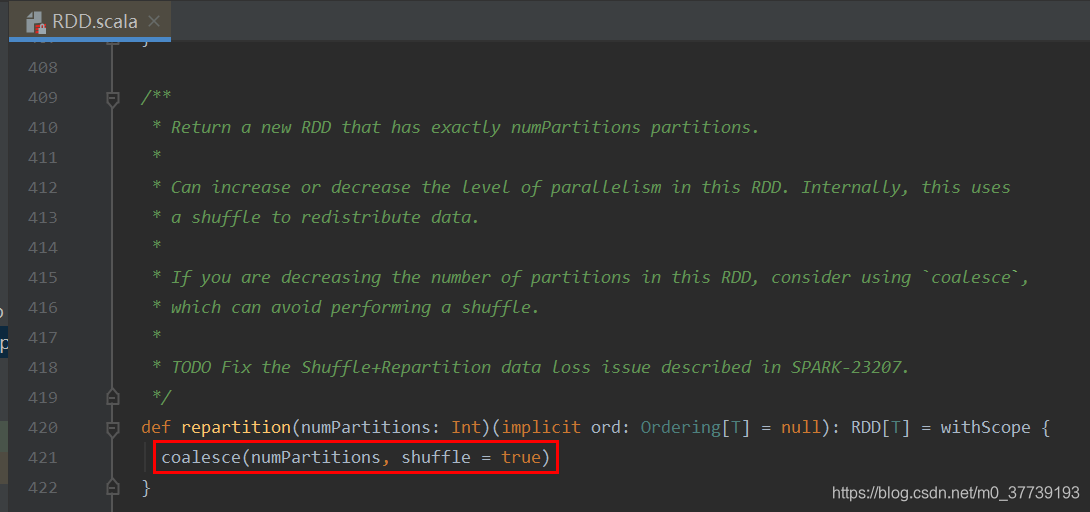
5.coalesce和repartition:
我们常认为coalesce不产生shuffle会比repartition 产生shuffle效率高,而实际情况往往要根据具体问题具体分析,coalesce效率不一定高,有时还有大坑,大家要慎用。 coalesce 与 repartition 他们两个都是RDD的分区进行重新划分,repartition只是coalesce接口中shuffle为true的实现
假设源RDD有N个分区,需要重新划分成M个分区:
- 如果N<M。一般情况下N个分区有数据分布不均匀的状况,利用HashPartitioner函数将数据重新分区为M个,这时需要将shuffle设置为true(repartition实现,coalesce也实现不了)。
- 如果N>M并且N和M相差不多,(假如N是1000,M是100)那么就可以将N个分区中的若干个分区合并成一个新的分区,最终合并为M个分区,这时可以将shuff设置为false(coalesce实现),如果M>N时,coalesce是无效的,不进行shuffle过程,父RDD和子RDD之间是窄依赖关系,无法使文件数(partiton)变多。 总之如果shuffle为false时,如果传入的参数大于现有的分区数目,RDD的分区数不变,也就是说不经过shuffle,是无法将RDD的分区数变多的
- 如果N>M并且两者相差悬殊,这时你要看executor数与要生成的partition关系,如果executor数 <= 要生成partition数,coalesce效率高,反之如果用coalesce会导致(executor数-要生成partiton数)个excutor空跑从而降低效率。如果在M为1的时候,为了使coalesce之前的操作有更好的并行度,可以将shuffle设置为true。
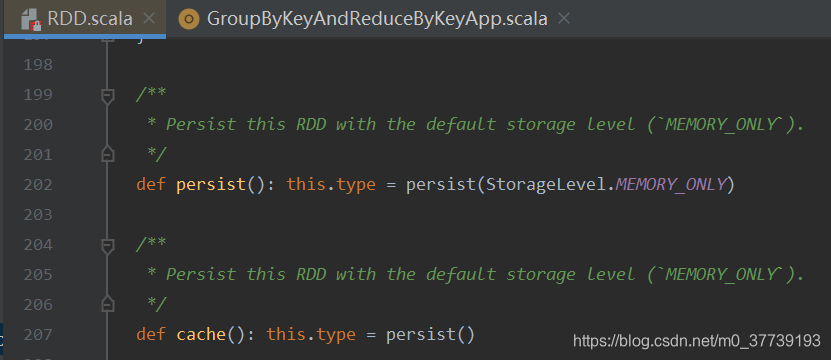
6.cache和persist:
cache调用的是persist(),persist调用的是persist(StorageLevel.MEMORY_ONLY),我们从源码中就可以看出来:
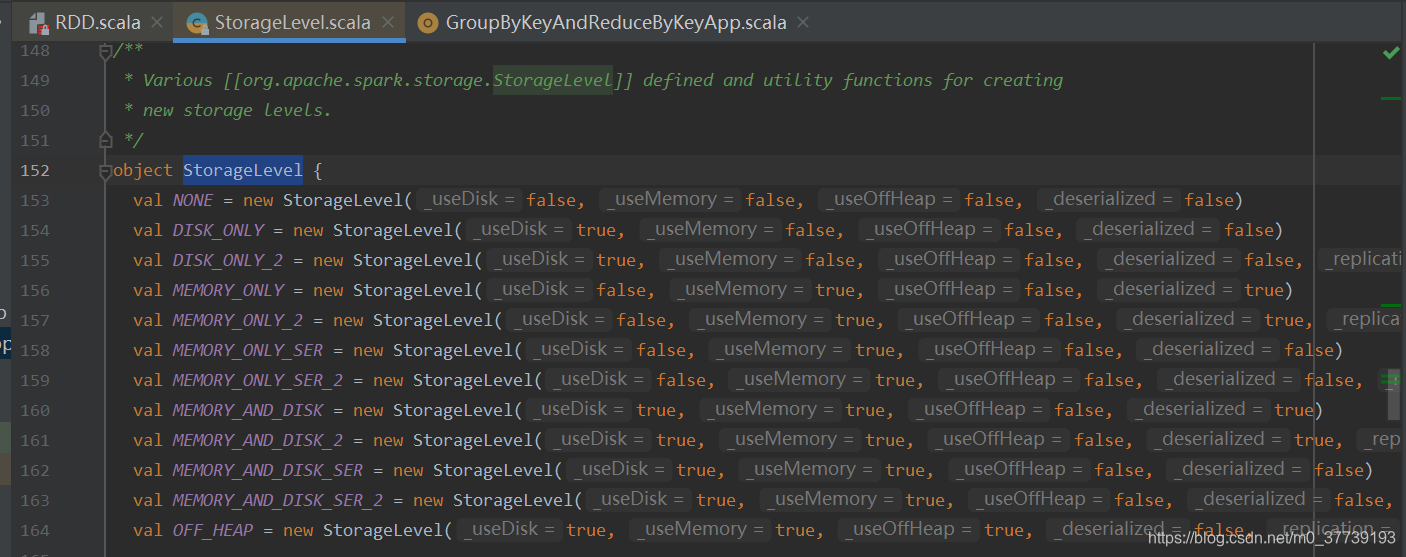
StorageLevel有很多种,我们可以看源码:
如何选择合适的存储策略可以参考官网:RDD Persistence
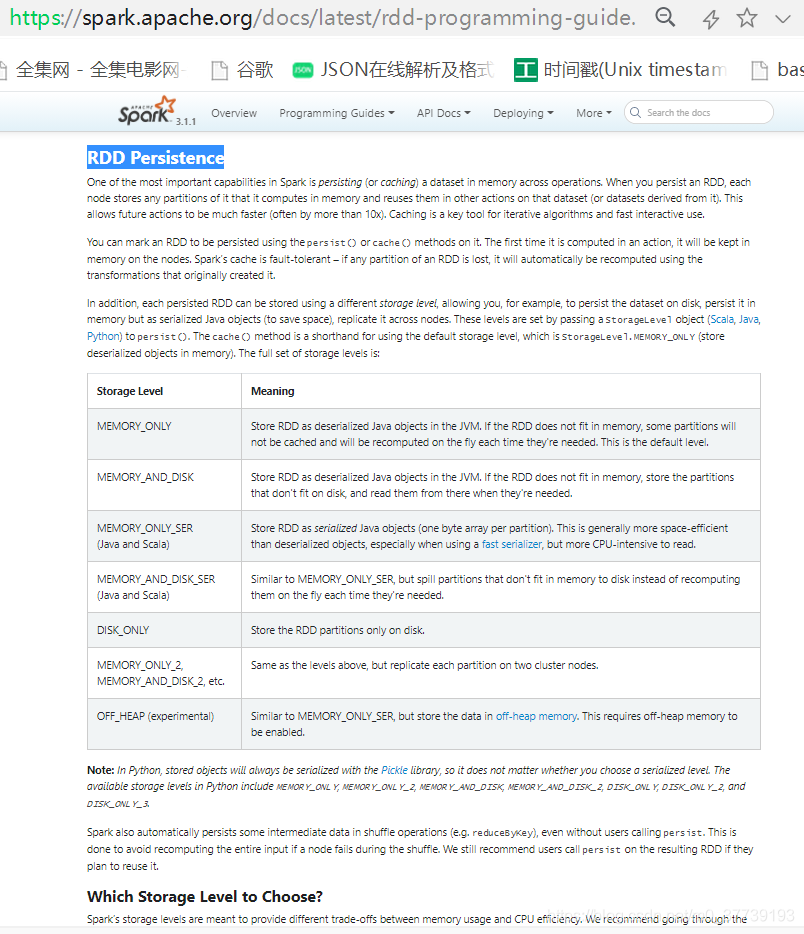
总结:cache和persist都是用于将一个RDD进行缓存的,这样在之后使用的过程中就不需要重新计算了,可以大大节省程序运行时间。cache只有一个默认的缓存级别MEMORY_ONLY ,而persist可以根据情况设置其它的缓存级别。
二、合理的序列化整合Spark使用为性能提速
调优可参考官网(这部分讲的挺重要):Tuning Spark
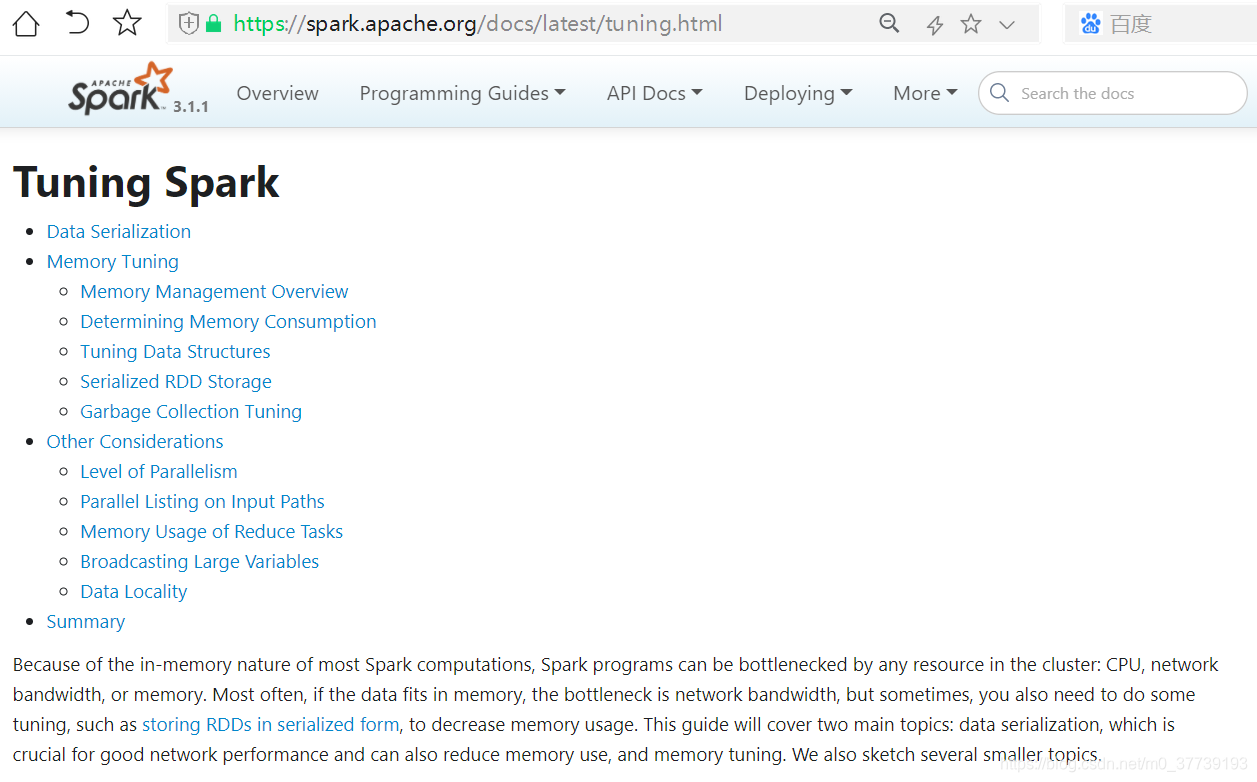
1.序列化概述:
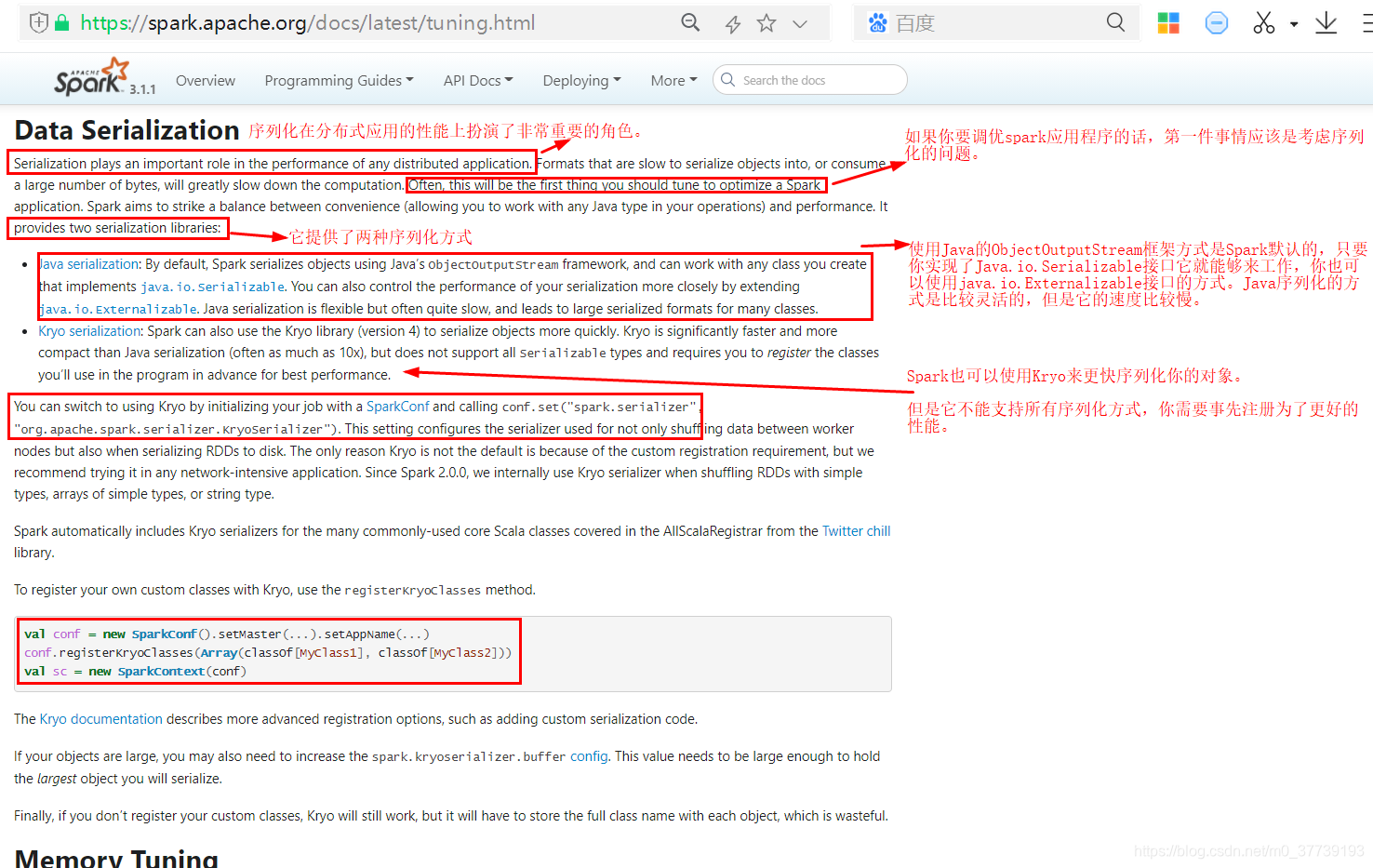
2.序列化性能测试:
(1)Java序列化性能测试:
编写测试代码SerializationApp.scala:
package com.huiq.test
import org.apache.spark.storage.StorageLevel
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable.ArrayBuffer
import scala.util.Random
object SerializationApp {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf()
// .setMaster("local[2]")
// .setAppName("SerializationApp")
val sc = new SparkContext(sparkConf)
val flag = sc.getConf.getInt("spark.flag", 0)
val infos = new ArrayBuffer[Info]()
val names = Array[String]("Huiq", "Zhangsan", "Lisi")
val genders = Array[String]("male", "female")
val addresses = Array[String]("beijing", "shanghai", "tianjin", "chengdu")
for (i<-1 to 1000000) {
val name = names(Random.nextInt(3))
val age = Random.nextInt(100)
val gender = genders(Random.nextInt(2))
val address = addresses(Random.nextInt(4))
infos += Info(name, age, gender, address)
}
val rdd = sc.parallelize(infos)
if (flag == 0) {
rdd.persist(StorageLevel.MEMORY_ONLY)
} else {
rdd.persist(StorageLevel.MEMORY_ONLY_SER)
}
println(rdd.count())
Thread.sleep(1000 * 60)
sc.stop()
}
case class Info(name:String, age:Int, gender:String, address:String)
}
生成jar包并上传到装有Spark集群的服务器上:
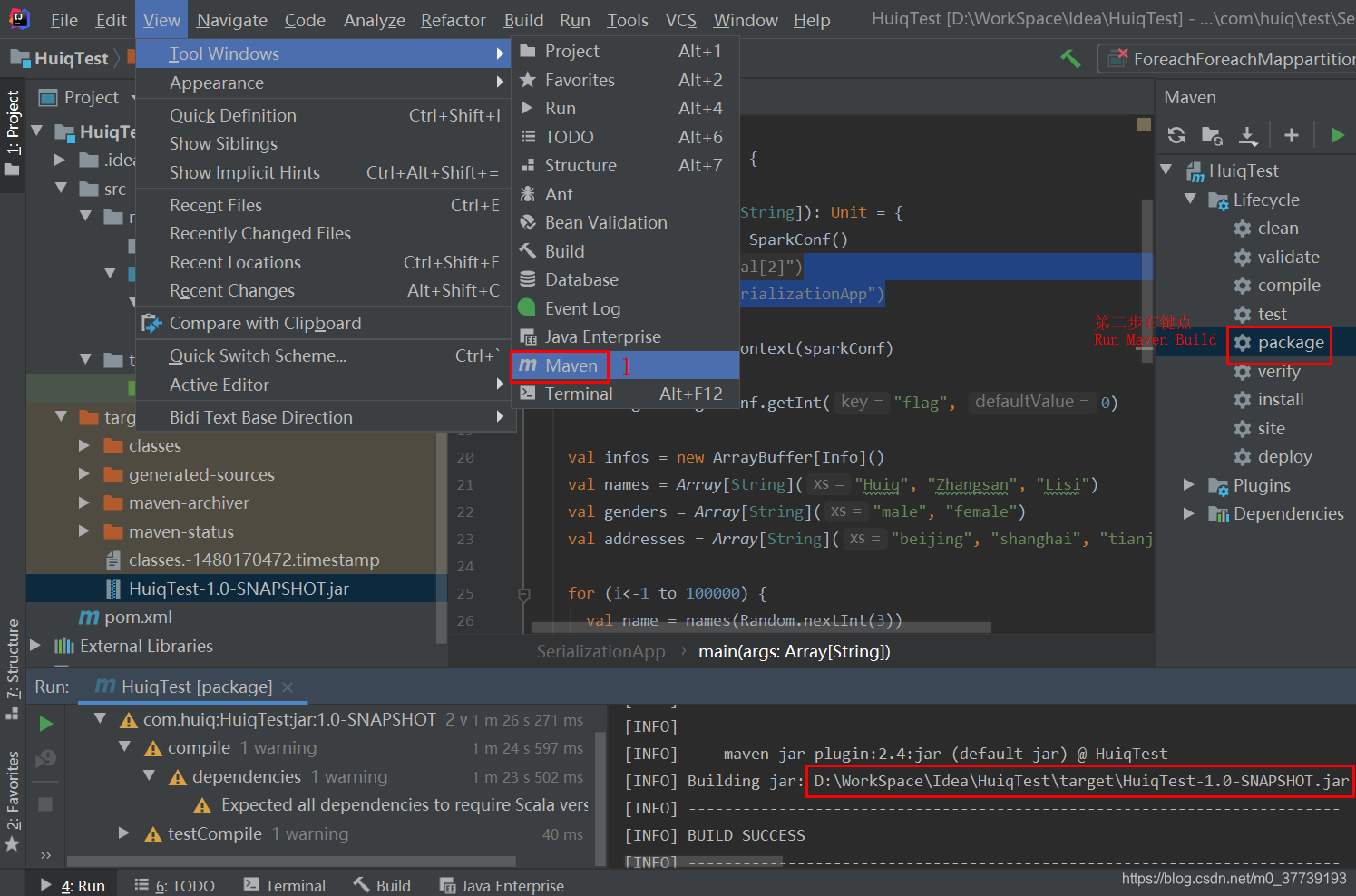
执行命令(Java方式采用MEMORY_ONLY的缓存策略):
spark-submit --class com.huiq.test.SerializationApp --master local[2] /mnt/huiq/HuiqTest-1.0-SNAPSHOT.jar

执行命令(Java方式采用MEMORY_ONLY_SER方式缓存策略):
spark-submit --class com.huiq.test.SerializationApp --master local[2] --conf spark.flag=1 /mnt/huiq/HuiqTest-1.0-SNAPSHOT.jar

缓存策略如何选择可参考官网:Which Storage Level to Choose?
(2)Java序列化性能测试:
修改SerializationApp.scala为:
package com.huiq.test
import org.apache.spark.storage.StorageLevel
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable.ArrayBuffer
import scala.util.Random
object SerializationApp {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf()
// .set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
// 使用Kryo要先注册
// sparkConf.registerKryoClasses(Array(classOf[Info]))
val sc = new SparkContext(sparkConf)
val infos = new ArrayBuffer[Info]()
val names = Array[String]("Huiq", "Zhangsan", "Lisi")
val genders = Array[String]("male", "female")
val addresses = Array[String]("beijing", "shanghai", "tianjin", "chengdu")
for (i<-1 to 1000000) {
val name = names(Random.nextInt(3))
val age = Random.nextInt(100)
val gender = genders(Random.nextInt(2))
val address = addresses(Random.nextInt(4))
infos += Info(name, age, gender, address)
}
val rdd = sc.parallelize(infos)
rdd.persist(StorageLevel.MEMORY_ONLY_SER)
println(rdd.count())
Thread.sleep(1000 * 60)
sc.stop()
}
case class Info(name:String, age:Int, gender:String, address:String)
}
执行命令:
spark-submit --class com.huiq.test.SerializationApp --master local[2] --conf spark.serializer=org.apache.spark.serializer.KryoSerializer /mnt/huiq/HuiqTest-1.0-SNAPSHOT.jar
Kryo没有注册(代码sparkConf.registerKryoClasses(Array(classOf[Info]))注释掉)采用MEMORY_ONLY_SER方式缓存策略:
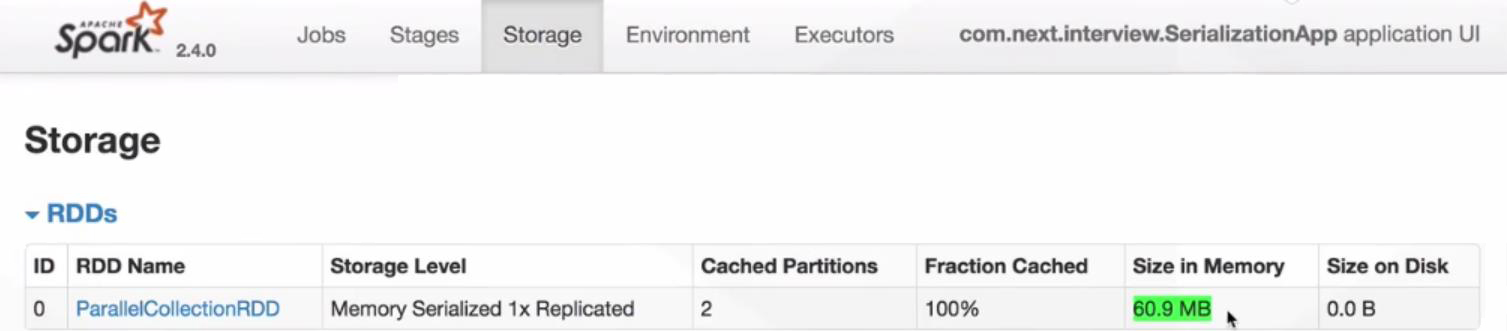
Kryo注册后(代码sparkConf.registerKryoClasses(Array(classOf[Info]))打开)采用MEMORY_ONLY_SER方式缓存策略:

原文链接:https://blog.csdn.net/m0_37739193/article/details/117287127
所属网站分类: 技术文章 > 博客
作者:niceboty
链接:http://www.javaheidong.com/blog/article/207702/83b1174f52a5f0f83fec/
来源:java黑洞网
任何形式的转载都请注明出处,如有侵权 一经发现 必将追究其法律责任
昵称:
评论内容:(最多支持255个字符)
---无人问津也好,技不如人也罢,你都要试着安静下来,去做自己该做的事,而不是让内心的烦躁、焦虑,坏掉你本来就不多的热情和定力