

shardingjdbc 实现分库分表
发布于2021-05-29 23:13 阅读(592) 评论(0) 点赞(5) 收藏(5)
前言
1,什么是分库分表?
就是把原本存储于一个库的数据分块存储到多个库上,把原本存储于一个表的数据分块存储到多个表上。
2,为什么要分库分表?
数据库中的数据量不一定是可控的,在未进行分库分表的情况下,随着时间和业务的发展,库中的表会越来越多,表中的数据量也会越来越大,相应地,数据操作,增删改查的开销也会越来越大;另外,由于无法进行分布式式部署,而一台服务器的资源(CPU、磁盘、内存、IO 等)是有限的,最终数据库所能承载的数据量、数据处理能力都将遭遇瓶颈。
Spring boot 整合 shardingjdbc 实现分库分表
一、分表操作
1,创建数据库 goods_db;
2,在 goods_db 中创建表 goods_1、goods_2;
3,约定规则,如果添加商品 id 是偶数把数据加入 goods_1,如果是偶数把数据加入 goods_2,sql 如下展示

4,配置 yml 文件
spring:
shardingsphere:
props:
sql:
show: true
datasource:
names: master,slave #对应下面主从库
master:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://192.168.1.12:3306/goods_db?useUnicode=true&characterEncoding=UTF-8&allowMultiQueries=true&serverTimezone=Asia/Shanghai
username: root
password: 123456
slave:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://192.168.1.8:3306/goods_db?useUnicode=true&characterEncoding=UTF-8&allowMultiQueries=true&serverTimezone=Asia/Shanghai
username: root
password: 123456
# masterslave:
# load-balance-algorithm-type: round_robin #负载 轮询,当你有多个从库或者主库时
# name: ms
# master-data-source-name: master #设置主库
# slave-data-source-names: slave #设置从库
sharding:
master-slave-rules:
ds0:
master-data-source-name: master #定义节点ds0的主库
slave-data-source-names: slave #定义节点ds0的从库
tables:
goods:
actual-data-nodes: ds0.goods_$->{1..2} #绑定goods表所在节点 这里定义goods_${1..2} 表示有2个表,查询的时候会查所有表
table-strategy:
inline:
sharding-column: gid #分片规则的字段
algorithm-expression: goods_$->{gid % 2 + 1} # 指定分片策略 约定gid值是偶数添加到goods_1表,如果gid是奇数添加到goods_2表
# key-generator:
# column: gid
# type: SNOWFLAKE
5,插入 10 条数据
@Test
public void addGoods(){
for (int i = 0; i < 10; i++){
Goods good = new Goods();
good.setGid((10L+Long.parseLong(Integer.toString(i))));
good.setGname("iphone手机" + i);
good.setUser_id(10L);
good.setGstatus("1");
goodsService.save(good);
}
}
6,查看日志
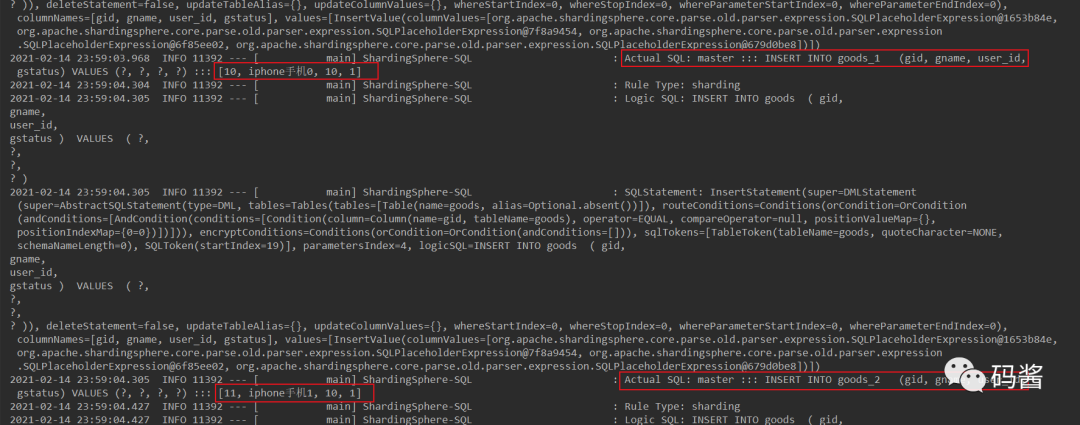
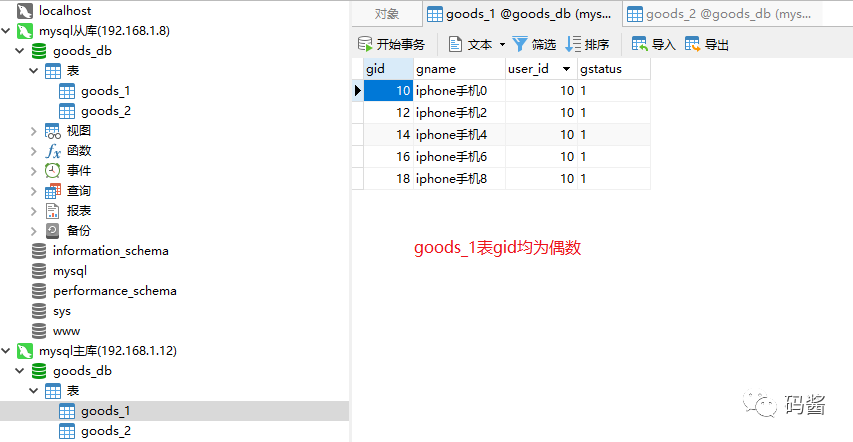
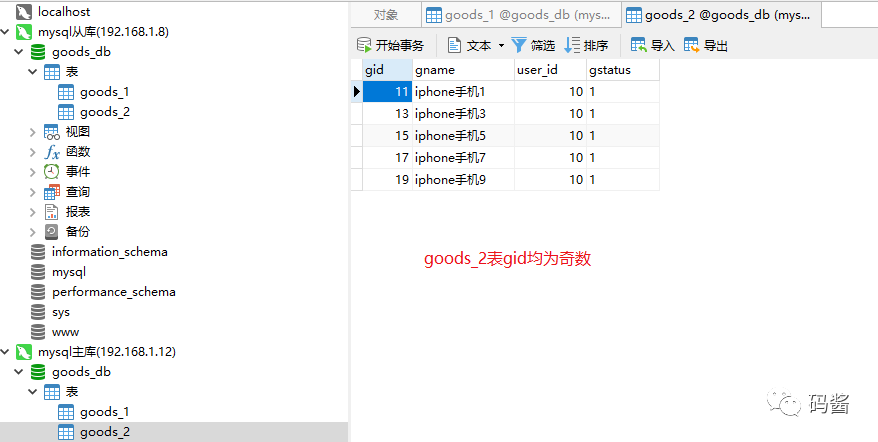
从日志中很明显可以看出,如果添加商品 gid 是偶数把数据加入 goods_1,如果是奇数把数据加入 goods_2
7,查询所有
@Test
public void listGoods() {
List<Goods> list = goodsService.list();
list.stream().forEach(r-> System.out.println(r.toString()));
}
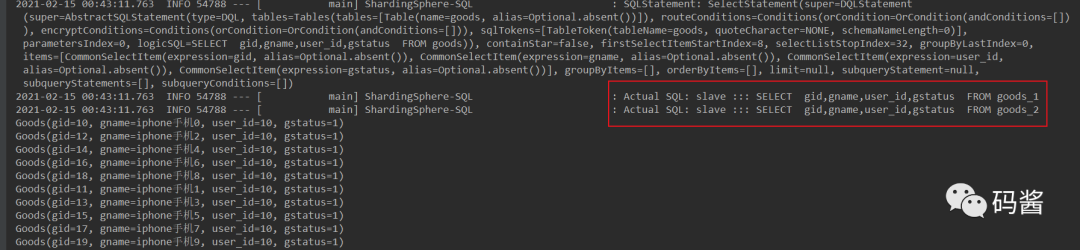
会查询从库下配置信息下 DS0 节点的 ds0.goods_$->{1…2},2 个表
8,根据 gid 查询
@Test
public void getGoodsById() {
QueryWrapper<Goods> query = new QueryWrapper<>();
query.eq("gid",14L);
Goods one = goodsService.getOne(query);
System.out.println(one);
}
会查询从库下,根据 gid 取模定位到表查询出从库数据 (这里查询的即为 goods_1)

二、分库操作
分库操作同样也很简单,yml 文件配置分表使用 table-strategy,配置分库使用 database-strategy。小伙伴们可以自己动手试试…
原文链接:https://blog.csdn.net/u012796085/article/details/117375410
所属网站分类: 技术文章 > 博客
作者:听说你很拽
链接:http://www.javaheidong.com/blog/article/207794/00e7ad5cc54f0c0d8da4/
来源:java黑洞网
任何形式的转载都请注明出处,如有侵权 一经发现 必将追究其法律责任
昵称:
评论内容:(最多支持255个字符)
---无人问津也好,技不如人也罢,你都要试着安静下来,去做自己该做的事,而不是让内心的烦躁、焦虑,坏掉你本来就不多的热情和定力