

JVM知识点
发布于2021-06-08 09:53 阅读(1341) 评论(0) 点赞(9) 收藏(2)
类加载的过程:加载->连接(验证,准备,解析)->初始化->使用->卸载
加载:查找并加载类文件的二进制数据
连接:将已经读入内存的类的二进制数据合并到JVM运行时环境中去,包含以下几个步骤:1)验证:确保被加载的类的正确性 2)准备:为类的静态变量分配内存并初始化他们 3)解析:把常量池中的符号引用转换成直接引用
初始化:为类的静态变量赋初始值
类加载要完成的功能
1.通过类的全限定名来获取该类的二进制字节流
2.把二进制字节流转化为方法区的运行时数据结构
3.在堆上创建一个java.lang.Class对象(对象.getClass()),用来封装类在方法区内的数据结构,并向外提供了访问方法区内数据结构的接口
加载类的方式
1.最常见的方式:本地文件系统中加载,从jar等归档文件中加载
2.动态的方式:将java源文件动态编译成class
3.其他方式:网络下载,从专有数据库中加载等等
类加载器
java虚拟机自带的加载器包括以下几种:
1.启动类加载器BootstrapClassLoader
2.扩展类加载器ExtensionClassLoader (jdk9之后是平台类加载器PlatformClassLoader)
3.应用程序类加载器AppClassLoader (我们写的类就是它来加载的)
4.用户自定义的加载器,是java.lang.ClassLoader的子类,用户可以定制类的加载方式,自定义类加载器的加载顺序是在所有系统类加载器的后面
类加载器的关系
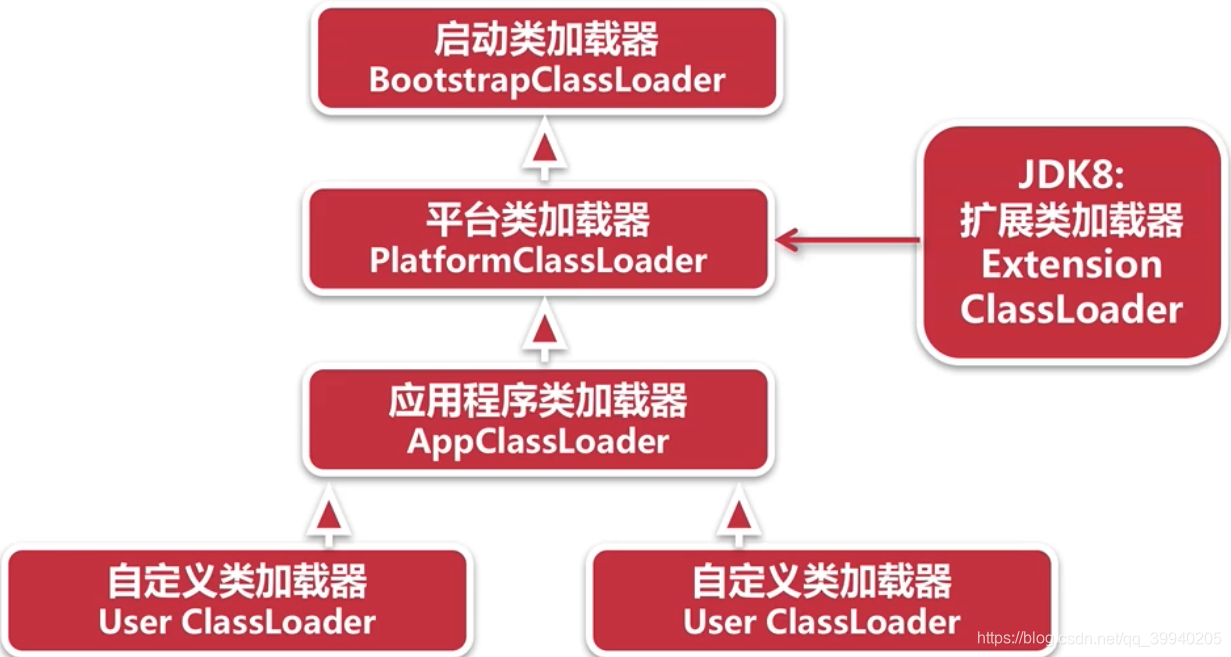
类加载器说明
1.启动类加载器:用于加载启动的基础模块类,比如:java.base ,java.management ,java.xml等等。启动类加载器不允许被改变和使用,String.getClass().getClassLoader()=null,返回的是null
2.平台类加载器:用于加载一些平台相关的模块,比如:java.scripting ,java.compiler* ,java.corba* 等等
3.应用程序类加载器:用于加载应用级别的模块,比如:jdk.compiler ,jdk.jartool ,jdk.jshell等等,还加载classpath路径中的所有类库
4.java程序不能直接引用启动类加载器,直接设置classLoader为null,默认就使用启动类加载器
5.类加载器并不需要等到某个类“首次主动使用”的时候才加载它,jvm规范允许类加载器在预料到某个类将要被使用的时候就预先加载它
6.如果在加载的时候.class文件缺失,会在该类首次主动使用时报LinkageError错误,如果一直没被使用就不会报错
双亲委派模型
JVM中的ClassLoader通常采用双亲委派模型,要求除了启动类加载器外,其余的类加载器都要有父级加载器。这里的父子关系是组合而不是继承,工作过程如下:
1.一个类加载器收到类加载请求后,首先搜索它的内建加载器定义的所有“具名模块”
2.如果找到了合适的模块定义,将会使用该加载器来加载
3.如果class没有在这些加载器定义的具名模块中找到,那么将会委托给父级加载器,直到启动类加载器
4.如果父级加载器也不能完成加载请求,比如在它的搜索路径下找不到这个类,那么子类加载器才来加载
5.在类路径下找到的类将成为这些加载器的无名模块
双亲委派模型说明
1.双亲委派模型对于保证java程序的稳定运行很重要
①避免同样的字节码重复加载
②出于安全性考虑,防止javaAPI中的类被随意替换
2.实现双亲委派的代码在java.lang.ClassLoader的loadClass()方法中,如果自定义类加载器的话,推荐覆盖实现findClass()方法
3.如果有一个类加载器能加载某个类,称为定义类加载器,所有能成功返回该类的Class的类加载器都被称为初始类加载器
4.如果没有指定父加载器,默认就是启动类加载器
5.每个类加载器都有自己的命名空间,命名空间由该加载器及其所有父加载器所加载的类构成,不同的命名空间,可以出现类的全限定名相同的情况
6.运行时包由同一个类加载器的类构成,决定两个类是否属于同一个运行时包,不仅要看全限定名是否一样,还要看定义类加载器是否相同。只有属于同一个运行时包的类才能实现相互包内可见
破坏双亲委派模型
1.双亲委派模型有个问题:父加载器无法向下识别子加载器加载的资源
2.为了解决这个问题,引入了线程上下文类加载器,可以通过Thread的setContentClassLoader()进行设置
java.sql.DriverManager源码
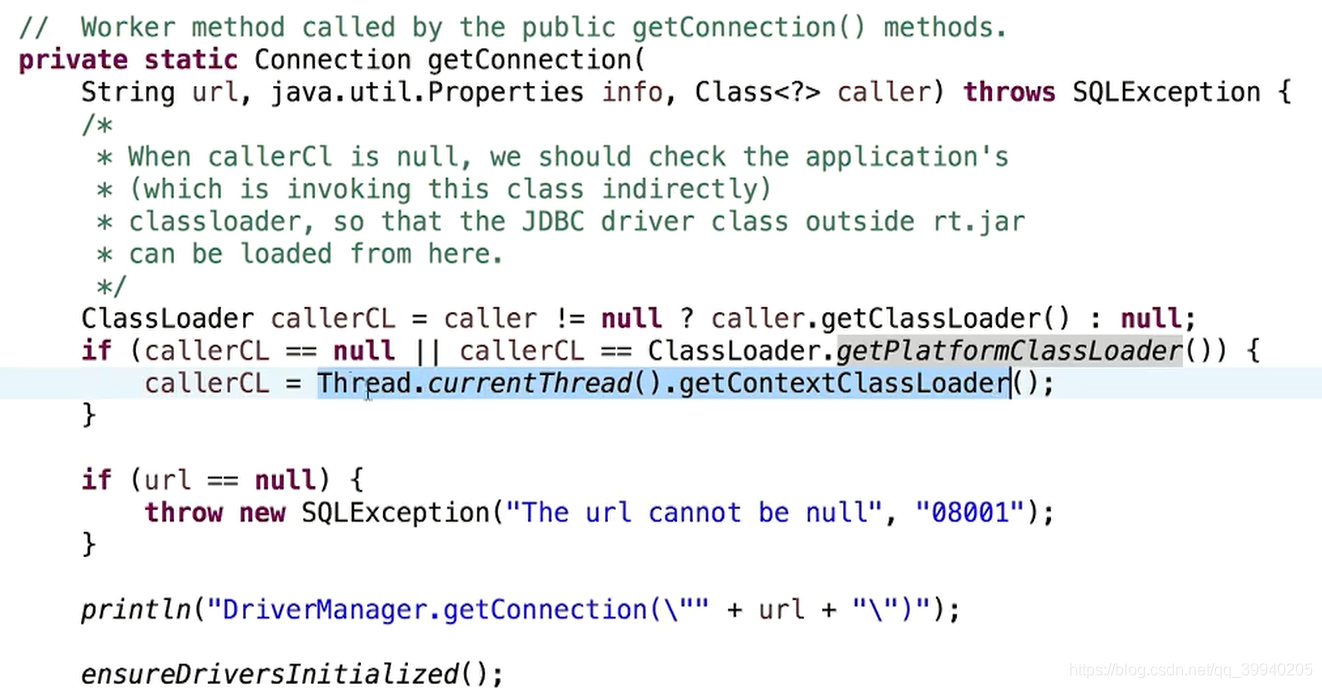
3.另外一种典型的情况就是实现热替换,比如OSGI的模块化热部署,它的类加载器就不是严格按照双亲委派模型,可能在平级的类加载器中执行了
类连接主要验证的内容
1.类文件结构检查:按照JVM规范规定的类文件结构进行
2.元数据验证:对字节码描述的信息进行语义分析,保证其符合java语言规范要求
3.字节码验证:通过对数据流和控制流进行分析,确保程序语义是合法和符合逻辑的。这里主要对方法体进行校验
4.符号引用验证:对类自身以外的信息,也就是常量池中的各种符号引用,进行匹配校验
类连接中的解析
所谓解析就是把常量池中的符号引用转换成直接引用发的过程
符号引用:以一组无歧义的符号来描述所引用的目标,与虚拟机的实现无关
直接引用:直接指向目标的指针、相对偏移量、或是能间接定位到目标的句柄,和虚拟机的实现相关
主要针对:类、接口、字段、类方法、接口方法、方法类型、方法句柄、调用点限定符
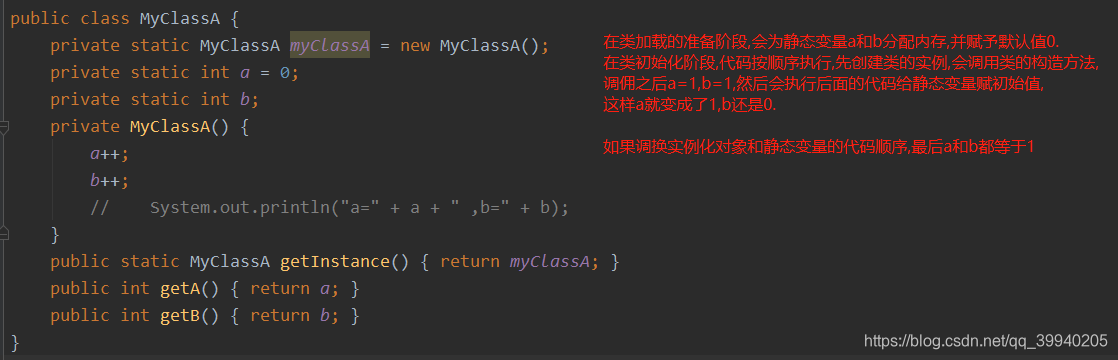
类的初始化
类的初始化就是为类的静态变量赋初始值,或者说是执行类构造器<init>方法的过程 (不是实例构造器方法)
1)如果类还没有加载和连接,就先加载和连接
2)如果类存在父类,且父类没有初始化,就先初始化父类
3)如果类中存在初始化语句,就依次执行这些初始化语句
4)如果是接口:
a.初始化一个类的时候,并不会先初始化它实现的接口
b.初始化一个接口时,并不会初始化它的父接口
c.只有当程序首次使用接口里面的变量或者调用接口的方法时,才会初始化接口
5)调用ClassLoader类的loadClass方法来加载类的时候,并不会初始化这个类,加载类不是对类的主动使用
类的初始化时机
java程序对类的使用分为主动使用和被动使用。JVM在每个类或接口“首次主动使用”时才初始化他们;被动使用类不会导致类的初始化。
主动使用的情况:
a.创建类实例
b.访问某个类或接口的静态变量
c.调用类的静态方法
d.反射某个类
e.初始化某个类的子类,而父类还没有初始化
f.JVM启动的时候运行的主类
g.定义了default方法的接口,当接口的实现类初始化时
被动使用的情况:
1.通过子类去调用父类的静态变量 。例如MyChidl.parentStr,不会初始化子类,会初始化父类
2.数组的方式。例如MyChild[] mcs = new MyChild[2],不会初始化类
3.访问常量也不会初始化类。例如public static final String childStr = "now in child!"
类的初始化机制和顺序
类的卸载
当代表一个类的Class对象不在被引用,那么Class对象的生命周期就结束了,对应的在方法区中的数据也会被卸载
JVM自带的类加载器加载的类。是不会卸载的。由用户自定义的类加载器加载的类是可以卸载的
JVM内存分配基础
JVM的简化架构

运行时数据区:包括方法区、虚拟机栈、本地方法栈、堆、程序计数器(PC寄存器)
PC寄存器:
1.每个线程都拥有一个PC寄存器,是线程私有的,用来存储指向下一条指令的地址,也可以看着是当前程序所执行的字节码的行号指示器,也可以看着是程序流的指示器
2.在创建线程的时候创建相应的PC寄存器
3.执行本地方法(执行JNI方法)时,PC寄存器的值为undefined
4.是一块比较小的内存空间,是唯一一个在JVM规范中没有规定OutOfMemoryError的内存区域,不会内存溢出
java栈
1.栈由一系列帧组成,是线程私有的
2.帧用来保存一个方法的局部变量表、操作数栈(java没有寄存器,所有参数传递使用操作数栈)、常量池指针、动态链接、方法返回值等
3.每一次方法调用创建一个帧,并压栈,退出方法的时候,修改栈顶指针就可以把栈桢中的内容销毁
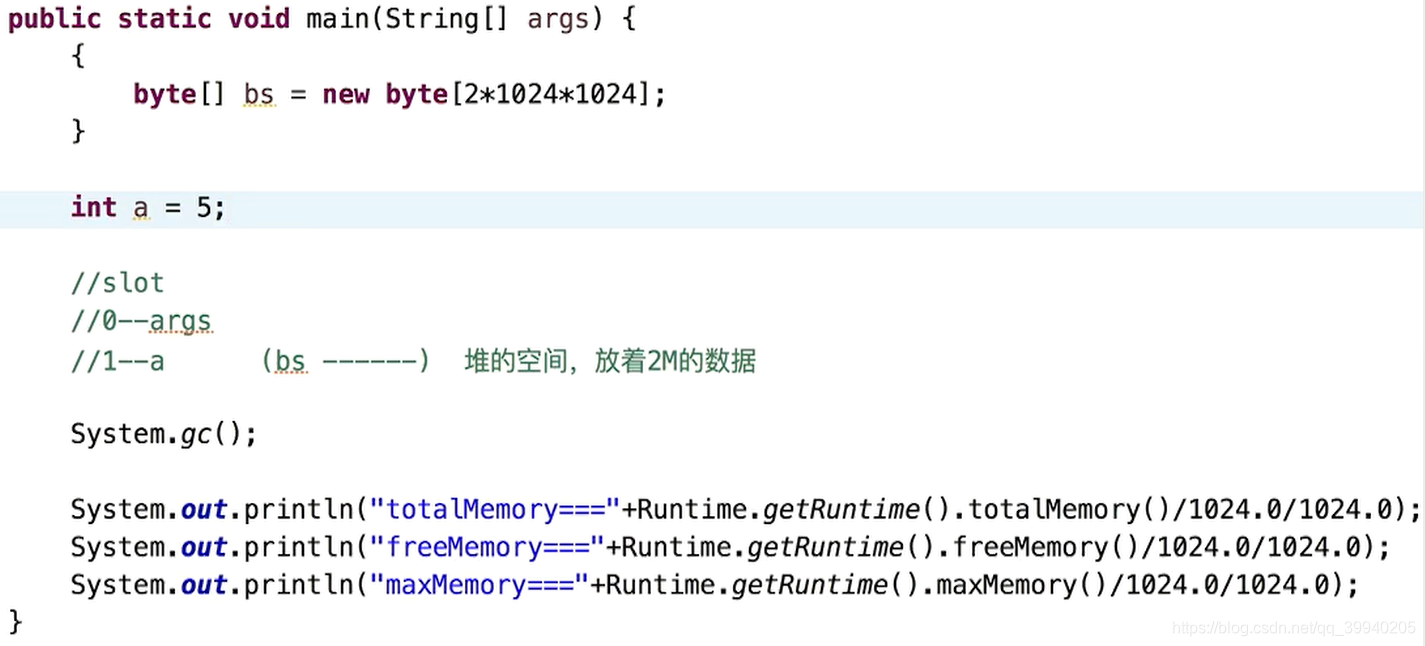
4.局部变量表存放了编译期可知的各种基本数据类型和引用类型,每个slot(插槽)存放32位的数据,long、double占两个槽位
5.栈的优点:存取速度比堆块,仅次于寄存器
6.栈的缺点:存在栈中的数据大小、生命周期是在编译期决定的,缺乏灵活性
java堆
用来存放应用系统创建的对象和数组,所有线程共享java堆
GC主要管理堆空间
堆的优点:运行期动态分配内存大小,自动进行垃圾回收
堆的缺点:效率相对较慢
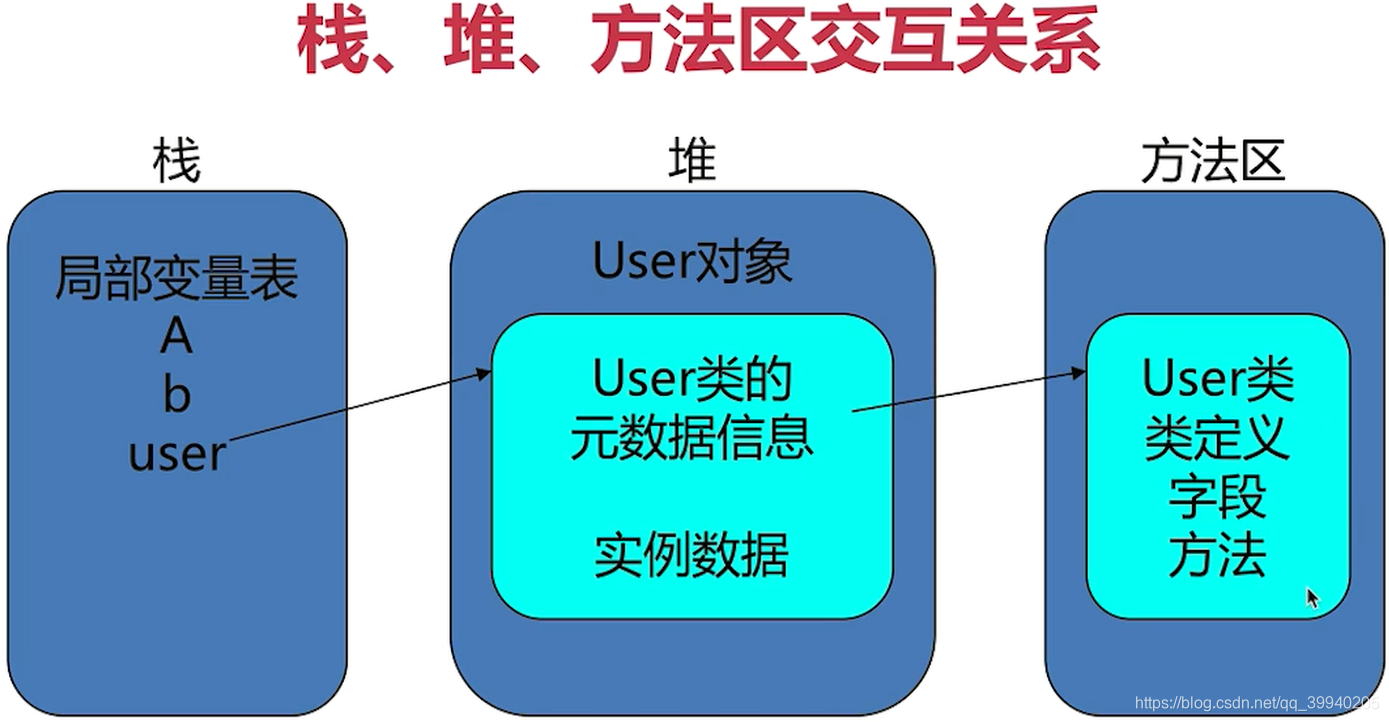
方法区
方法区是线程共享的,用来保存类的结构信息(运行时的常量池、静态变量、常量、类元信息)
通常和元空间关联在一起,具体跟JVM的实现和版本有关
JVM规范把方法区描述为堆的一个逻辑部分,但它有一个别名Non-heap(非堆),是为了与java堆区分开
运行时常量池
是Class文件中每个类或接口的常量池表,在运行期间的表示形式,通过包括:类的版本,字段、方法、接口等信息
在方法区中分配
通常在加载类或接口到JVM中后,就创建相应的运行时常量池
本地方法栈
在JVM中用来支持native方法执行的栈就是本地方法栈。是线程私有的
Java堆内存概述
java堆用来存放应用系统创建的对象和数组,所有线程共享java堆
java堆是在运行期动态分配内存大小,自动进行垃圾回收
java垃圾回收主要就是回收堆内存,对分代GC来说,堆也是分代的
java堆的结构
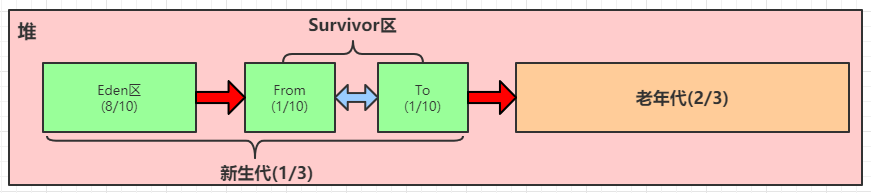
1. 新生代用来存放新分配的对象;新生代中经过垃圾回收,没有被回收掉的对象,被复制到老年代
2.老年代存储的对象比新生代存储的对象的年龄大的多
3.老年代存储一些大对象,大对象会直接分配到老年代
4.整个堆的大小=新生代+老年代
5.新生代=Eden去+存活区(Survivor)
6.从JDK8开始去掉了持久代(用来存放Class、Method等元信息的区域),取而代之的是元空间(MetaSpace),元空间并不在虚拟机里面,而是直接使用本地内存
对象的内存布局
对象在内存中存储的布局(以HotSpot虚拟机为例)分为:对象头,实例数据和对齐填充
1.对象头,包括两部分
(1)Mark Word:存储对象自身的运行数据,如:HashCode、GC分代年龄、锁状态标志等
(2)类型指针:指向它的类元信息(在方法区)的指针
2.实例数据:真正存放对象实例数据的地方
3.对齐填充:这部分不一定存在,也没有特别的含义,仅仅是占位符。因为HotSpot要求对象起始地址都是8字节的整数倍,如果不是,就对齐
对象的访问定位
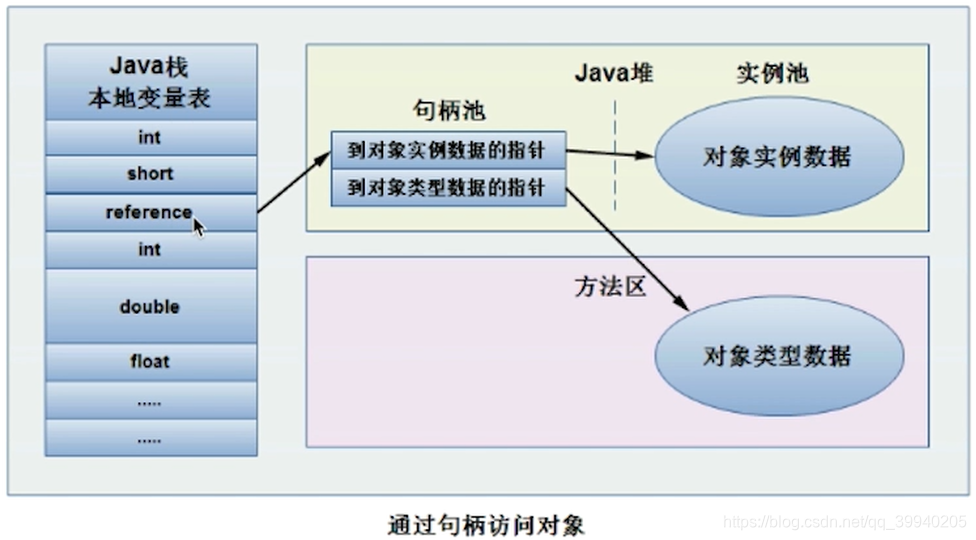
.对象的访问定位:在JVM规范中只规范了reference类型是一个指向对象的引用,但没有规定这个引用具体如何去定位、访问堆中对象的具体位置
因此对象的访问方式取决于JVM的实现,目前主流的有:使用句柄或使用指针两张方式
1.使用句柄:Java堆中会划分出一块内存来作为句柄池,reference中存储句柄的地址,句柄中存储对象实例数据和类元数据的地址
2.使用指针:java堆中存放访问类元数据的地址,reference存储的是对象实例数据的地址

Java内存分配参数
Trace跟踪参数 (版本jdk9+)
打印GC的简要信息:-Xlog:gc
打印GC详细信息:-Xlog:gc*
指定GC log的位置,以文件输出:-Xlog:gc:garbage-collection.log
每一次GC后,都打印堆信息:-Xlog:gc+heap=debug
Java堆的参数
-Xms:堆的大小,默认为物理内存的1/64
-Xmx:堆的最大值,默认为物理内存的1/4
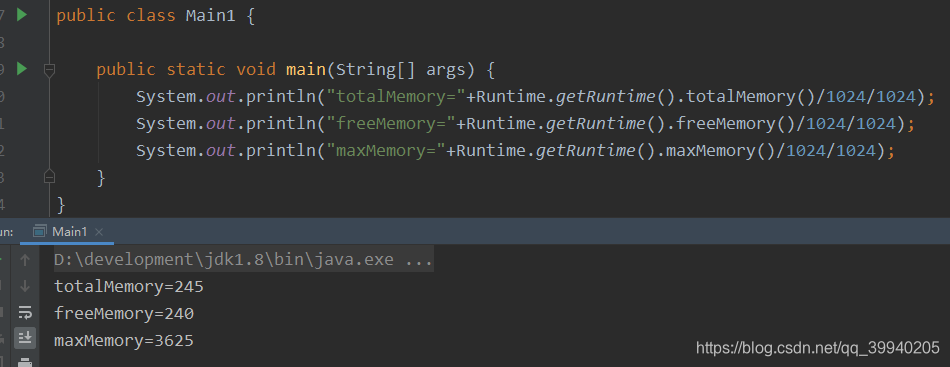
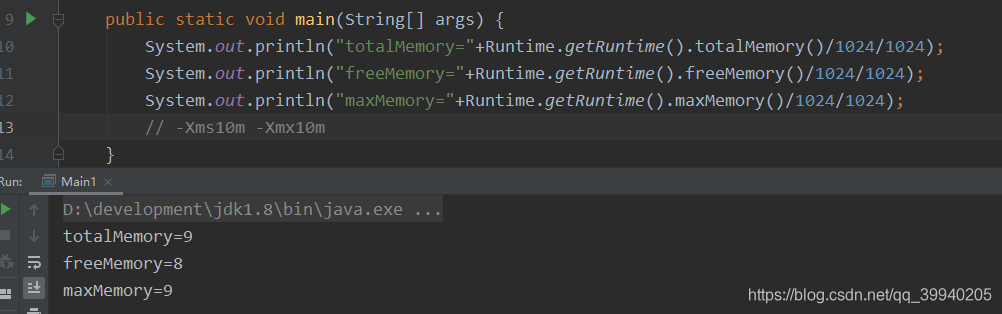
建议-Xms和-Xmx设置相等,避免每次GC后调整堆的大小,减少系统内存分配的开销
-Xmn:新生代的大小,默认整个堆的3/8 (JDK8是1/3)
设置垃圾回收器 -XX:+UseConcMarkSweepGC 使用CMS垃圾收集器 -XX:+UseG1GC 使用G1收集器
-XX:+UseConcMarkSweepGC -Xms10m -Xmx10m -Xmn3m -Xlog:gc

保存GC日志
-XX:+UseConcMarkSweepGC -Xms10m -Xmx10m -Xmn3m -Xlog:gc+heap=debug:logs/mygc.log -XX:+HeapDumpOnOutOfMemoryError
-XX:NewRatio:老年代与新生代的比值。如果设置Xms=Xmx,且设置了Xmn的情况下,该参数不用设置
-XX:SurvivorRatio:Eden区和Survivor区的大小比值
-XX:+HeapDumpOnOutOfMemoryError:OOM时导出堆文件
-XX:+HeapDumpPath:导出OOM的路径
-XX:OnOutOfMemoryError:在OOM时,执行一个脚本
Java栈的参数
-Xss:通常只有几百k,决定了函数调用的深度
元空间的参数
-XX:MetaspaceSize:元空间初始大小
-XX:MaxMetaspaceSize:最大空间,默认没有限制
-XX:MinMetaspaceFreeRatio:在GC之后,最小的Metaspace剩余空间容量的百分比
-XX:MaxMetaspaceFreeRatio:在GC之后,最大的Metaspace剩余空间容量的百分比
字节码执行引擎
概述
JVM的字节码执行引擎,功能就是输入字节码文件,然后对字节码进行解析并处理,最后输出执行结果
实现方式有通过解释器直接解释字节码文件,或者是通过即时编译器产生本地代码,也就是编译执行,当然也可能两者皆有
栈桢概述
栈桢是用于支持JVM方法调用和方法执行的数据结构
栈桢随着方法的调用而创建,随着方法结束而销毁
栈桢里面存储了方法的局部表里表、操作数栈、动态链接、方法返回地址等信息
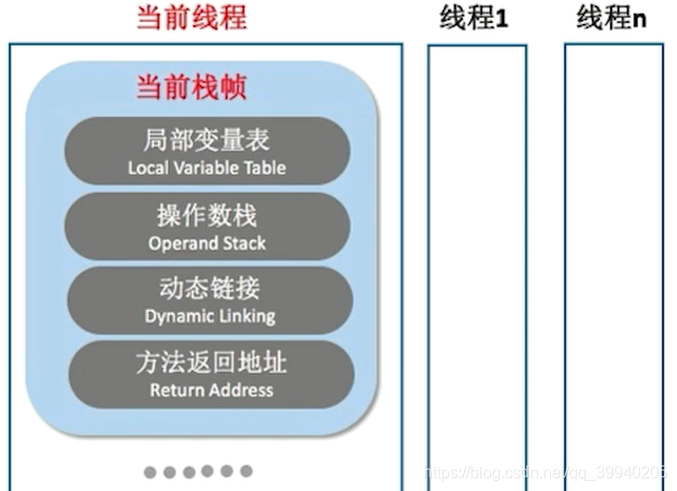
局部变量表:用来存放方法参数和方法内部定义的局部变量的存储空间
1.以变量槽slot为单位,一个slot槽存放32位以内的数据类型
2.对于64位的数据占2个slot
3.对于实例方法,第0位slot存放的是this,然后从1到n,依次分配给参数列表。静态方法是从0开始

4.然后根据方法体内部定义的变量顺序和作用域来分配slot
5.slot是复用的,以节省栈桢的空间,这种设计可能会影响到系统的垃圾收集行为
操作数栈
操作数栈:用来存放方法运行期间,各个指令操作的数据
1.操作数栈中元素的数据类型必须和字节码指令的顺序严格匹配
2.虚拟机在实现栈桢的时候可能会做一些优化,让两个栈桢出现部分重叠区域,以存放公用数据
动态链接
动态链接:每个栈桢持有一个指向运行时常量池中该栈桢所属方法的引用,以支持方法调用过程的动态链接
1.静态解析:类加载的时候,符号引用转换成直接引用
2.动态链接:运行期间转化为直接引用
方法返回地址
方法返回地址:方法执行后返回的地址
方法调用
方法调用:就是确定具体调用哪一个方法,不涉及方法内部的执行过程
1.部分方法是直接在类加载的解析阶段,就确定了直接引用关系
2.但是对于实例方法,也称虚方法,因为重载和多态,需要运行期动态委派
所属网站分类: 技术文章 > 博客
作者:想要飞翔的天使
链接:http://www.javaheidong.com/blog/article/219306/e52c5ed00c2af4114907/
来源:java黑洞网
任何形式的转载都请注明出处,如有侵权 一经发现 必将追究其法律责任
昵称:
评论内容:(最多支持255个字符)
---无人问津也好,技不如人也罢,你都要试着安静下来,去做自己该做的事,而不是让内心的烦躁、焦虑,坏掉你本来就不多的热情和定力