

MIT6.830 lab1 SimpleDb 实验报告
发布于2021-10-05 07:39 阅读(920) 评论(0) 点赞(6) 收藏(0)
一、环境搭建
1.课程官网:6.830/6.814: Database Systems
2.Github地址:simple-db-hw-2021
3.安装配置ant
二、实验概览
SimpleDB consists of:
- Classes that represent fields, tuples, and tuple schemas;(字段、元组(即记录)、模式)
- Classes that apply predicates and conditions to tuples;(描述元组)
- One or more access methods (e.g., heap files) that store relations on disk and provide a way to iterate through tuples
of those relations;(访问元组)- A collection of operator classes (e.g., select, join, insert, delete, etc.) that process tuples;(CRUD)
- A buffer pool that caches active tuples and pages in memory and handles concurrency control and transactions (neither
of which you need to worry about for this lab); and,(实现buffer pool及并发控制、事务)- A catalog that stores information about available tables and their schemas.
整个实验一共有6个lab,通过每一个lab的代码去实现一个简单的数据库,主要有:数据库的组织架构(字段、元组、模式、buffer pool等)、sql boy最爱的CRUD的实现、查询优化、事务与并发控制、崩溃与故障恢复。刚做完第一个lab,记录一下方便后面复习。
lab1主要是实现了整个数据库的整体架构,做完会对数据库是怎样组织我们平时的表会有较多的认识,当然,lab1并没有像MySQL那样去实现以B+树形式的聚簇索引来存储数据,主要还是按顺序存储,数据结构非常的简单。
lab1涉及的主要有这几个部分:Tuple(元组)、TupleDesc(table的metadata)、catalog(该数据库并没有过度区分catalog和schema,可以看成是一个schema)、BufferPool(缓冲池)、HeapPage(数据页)、HeapFile(disk上的文件)、SeqScan(全表顺序扫描),下面是各个部分的介绍与联系:
1.Tuple:元组,数据库上把一个有n列的table称作n元组,一个Tuple有多个字段。通俗来讲,一条记录就是一个元组,在该实验中体现为一个Tuple类的实例。一个Tuple由以下部分组成:a.TupleDesc:该元组的描述信息;b.fields:该记录各个字段的类型与值; c.RecordId:该记录在磁盘的位置。
2.TupleDesc:TupleDesc用来表示一个元组的描述信息,更准确来说应该是一个表的描述信息;
3.Catalog:Catalog是仅次于DataBase的抽象概念,一个DataBase可以有多个Catalog,一个Catalog有多个Schema,一个Schema有多张table,不过该数据库没有太过区分这三个概念,而在MySQL中也是用Schema来表示整个数据库包含的多张table。该lab中实现了一个Table类,并在Catalog类中使用一个HashMap来存放table id与table的映射关系。
4.BufferPool:BufferPool的基本单位是Page,每次从磁盘中(这里表现为DbFile)读取数据页到BufferPool,在数据库上的crud操作都是在Buffer Pool的Page中进行的(所以有脏页、故障恢复等)。该数据库的BufferPool默认是缓冲50个Page,每个Page的默认大小是4096bytes即4kb。lab1主要是实现getPage方法,从BufferPool中获取Page,如果获取不到,就在磁盘中获取,并保存到BufferPool中。当然,当BufferPool满了之后,需要有淘汰策略,后续的lab会实现,应该是使用LRU算法来做的。
5.HeapPage与HeapFile:HeapPage是Page接口的实现,是以顺序逻辑组织数据的一张数据页(后续会用b+树实现来替代),crud操作都是在Page上进行的。HeapPage既是BuffeerPool的基本单位也是HeapFile的基本单位。HeapFile是DbFile接口的实现,与磁盘中的文件交互,该数据中一张表的所有数据就是存到DbFile的File属性中,即一个磁盘的文件就是一张表的所有数据。
6.SeqScan:全表顺序扫描的实现,相当于select * from my_table.
这些组成部分的关系如下图所示:
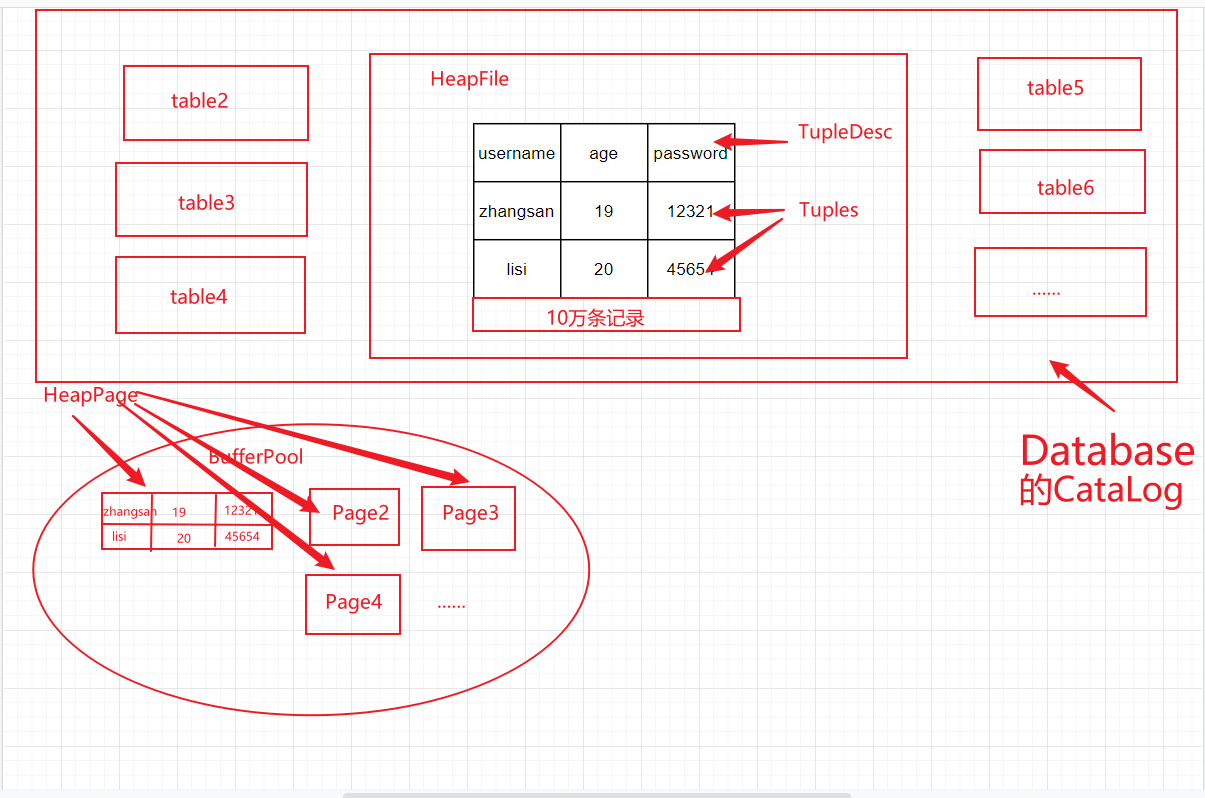
除了上述信息,该实验还提供了一个DataBase类,可以理解成一个数据库的全局信息,可以说是一个数据库的入口,主要由以下三部分组成:
catalog:存放实际的表格,而每张表格的描述信息应该放在了TupleDesc中;
BufferPool:实际进行crud操作的地方,buffer pool以page为单位从磁盘中读入。
LogFile:日志文件。
三、实验过程
Exercise1
Tuples in SimpleDB are quite basic. They consist of a collection of
Fieldobjects, one per field in theTuple.Fieldis an interface that different data types (e.g., integer, string) implement.Tupleobjects are created by the underlying access methods (e.g., heap files, or B-trees), as described in the next section. Tuples also have a type (or schema), called a tuple descriptor, represented by aTupleDescobject. This object consists of a collection ofTypeobjects, one per field in the tuple, each of which describes the type of the corresponding field.
exercise1主要是实现Tuple与TupleDesc这两个类的构造器和主要方法,较为简单。
Tuple:包含td,rid,fields三个属性,一条记录最基本的信息,其它的就是一些构造器,getter方法和迭代器等,看着注释实现就可以了。
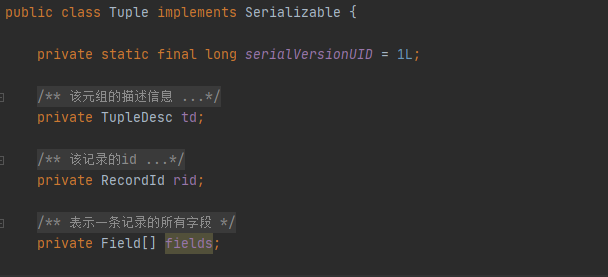
其中Field是字段的实现,点进去看可以看到主要是Type来存储字段类型
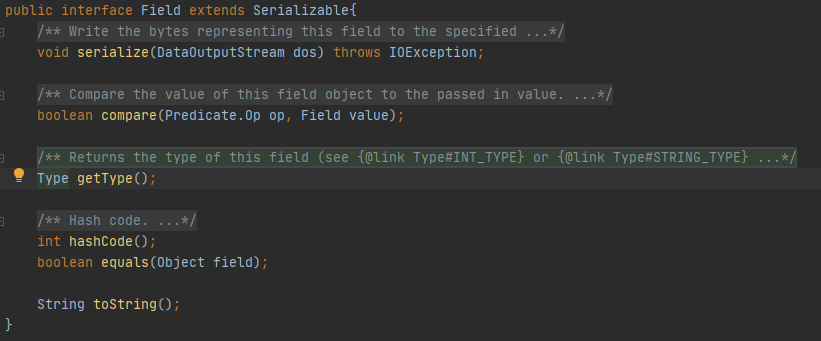
而Type是类型的枚举,该数据库支持int类型和String类型,类型信息描述都在里面,后面也可在Type中扩展数据类型:
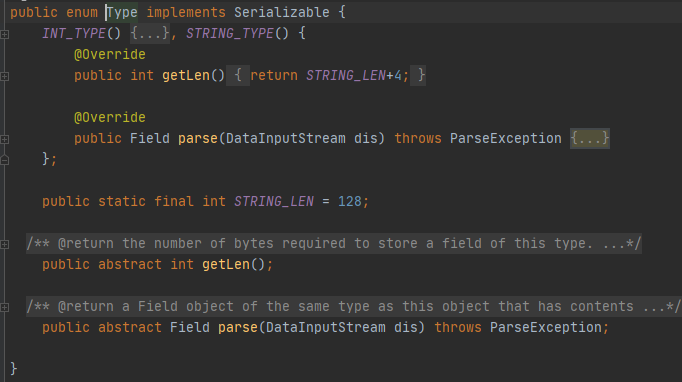
根据字段的类型,parse方法可以返回具体的Field实现类,即带有类型的Field,里面用value来存储字段值:
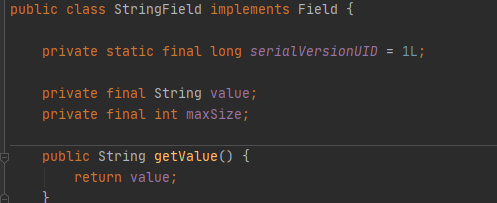
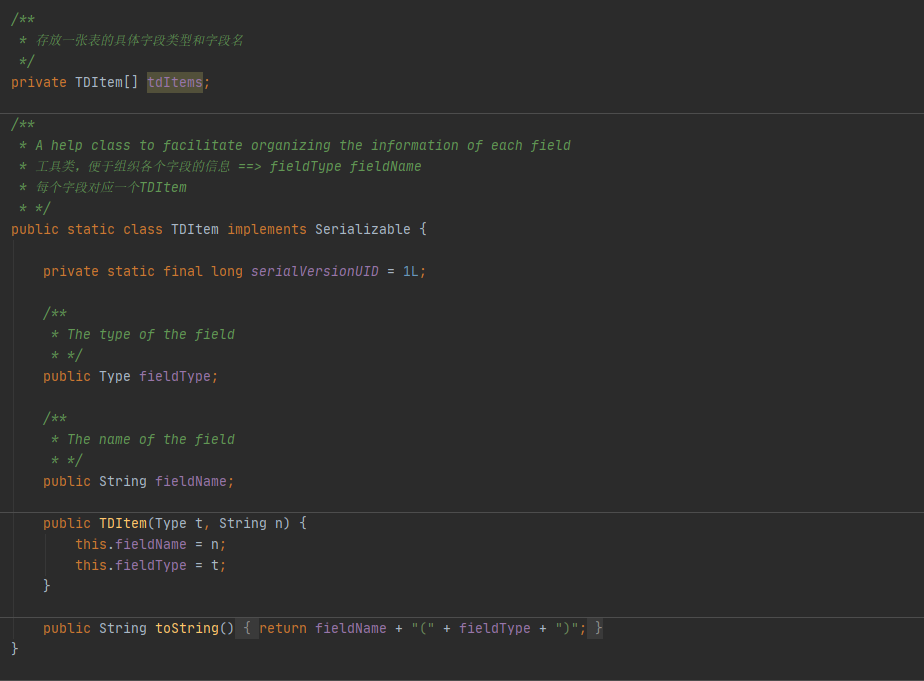
TupleDesc:TupleDesc主要是需要实现一个TDItem内部类来表示一个字段的描述信息,包括字段类型,字段名;TupleDesc中用一个TDItem数组来表示多个字段的描述信息,有了这个,后面做起来就简单很多了。
Exercise2
The catalog (class
Catalogin SimpleDB) consists of a list of the tables and schemas of the tables that are currently
in the database. You will need to support the ability to add a new table, as well as getting information about a
particular table. Associated with each table is aTupleDescobject that allows operators to determine the types and
number of fields in a table.The global catalog is a single instance of
Catalogthat is allocated for the entire SimpleDB process. The global
catalog can be retrieved via the methodDatabase.getCatalog(), and the same goes for the global buffer pool (
usingDatabase.getBufferPool()).
exercise2主要是实现Catalog.java这个类,这里的关键是在Catalog里实现一个Table类,来存放一张表格的信息;然后一个CataLog有多张表格,在Catalog里我们可以用map来存储tableid与table的映射关系;为了方便操作,我还多创建了一个存放table name与 table id映射关系的map:

Exercise3
The buffer pool (class
BufferPoolin SimpleDB) is responsible for caching pages in memory that have been recently read from disk. All operators read and write pages from various files on disk through the buffer pool. It consists of a fixed number of pages, defined by thenumPagesparameter to theBufferPoolconstructor. In later labs, you will implement an eviction policy(淘汰策略). For this lab, you only need to implement the constructor and theBufferPool.getPage()method used by the SeqScan operator. The BufferPool should store up tonumPagespages. For this lab, if more thannumPagesrequests are made for different pages, then instead of implementing an eviction policy, you may throw a DbException. In future labs you will be required to implement an eviction policy.
lab1无需实现淘汰策略,主要是实现getPage方法。根据PageId来查找BufferPool中有无该数据页,如果有直接返回,如果没有就从磁盘中获取,存入BufferPool中。其中BufferPool的容器是用map来存Page的,以pid的hashcode与Page建立映射关系。

Exercise4
A
HeapFileobject is arranged into a set of pages, each of which consists of a fixed number of bytes for storing
tuples, (defined by the constantBufferPool.DEFAULT_PAGE_SIZE), including a header. In SimpleDB, there is
oneHeapFileobject for each table in the database(一个HeapFile对应一张表). Each page in aHeapFileis arranged as a set of slots, each of
which can hold one tuple (tuples for a given table in SimpleDB are all of the same size). In addition to these slots,
each page has a header that consists of a bitmap with one bit per tuple slot. If the bit corresponding to a particular
tuple is 1, it indicates that the tuple is valid; if it is 0, the tuple is invalid (e.g., has been deleted or was never
initialized.) Pages ofHeapFileobjects are of typeHeapPagewhich implements thePageinterface. Pages are
stored in the buffer pool but are read and written by theHeapFileclass.
exercise4主要是实现以下三个类:
- src/java/simpledb/storage/HeapPageId.java
- src/java/simpledb/storage/RecordId.java
- src/java/simpledb/storage/HeapPage.java
关键是HeapPage的实现,HeapPage中的核心是数据是怎样HeapPage中组织的,这里主要是由header和tuples两个部分组成。其中,一条tuple在HeapPage中表示为一个slot,而header以bitmap的形式来表示第i个slot是否被占用,最低位表示第一个slot是否被占用。由于header是一个byte类型数据,所以最后一个字节并不一定都表示一个slot,也可能无意义:

除了基本的属性,关键的方法是计算一个Page能存多少条tuple和header占多少字节,讲义中给出了计算公式:
_tuples per page_ = floor((_page size_ * 8) / (_tuple size_ * 8 + 1))
headerBytes = ceiling(tupsPerPage/8)
代码实现如下:

有了上面这两个方法,就方便对属性进行初始化。当对数据页进行操作时,需要判断某个slot是否被占用,所有需要实现以下方法:

最后就是实现返回一个有效记录的iterator的方法:

Exercise5
exercise5主要是实现heapfile,HeapFile是DbFile的实现,是对磁盘文件操作的入口:

HeapFile要求我们实现一个readPage方法,根据PageId去从磁盘中读取数据。这里主要的难点是计算偏移量然后读取数据,这里需要先计算出offset,然后用seek移动指针,然后再开始读取,具体代码实现如下:

除了实现上述功能,HeapPage还要求我们实现一个迭代器用于遍历所有的tuple,注意这里的实现是先从BufferPool中读取数据,读取不到再从磁盘中读,直接调用readPage会出现OOM。实现如下:
/**
* HeapFile迭代器,用于遍历HeapFile的所有tuple;
* 需要使用上BufferPool.getPage(),注意一次不能读出HeapFile的所有tuples,不然会出现OOM
*/
private static class HeapFileIterator implements DbFileIterator {
private final TransactionId tid;
private final HeapFile file;
private Iterator<Tuple> it;
private int pageNo;
public HeapFileIterator(TransactionId tid, HeapFile file) {
this.tid = tid;
this.file = file;
}
@Override
public void open() throws DbException, TransactionAbortedException {
pageNo = 0;
it = getTupleIterator(pageNo);
}
/**
* 根据pageNo从buffer pool 或者磁盘读出HeapPage并返回其tuple的迭代器
* @param pageNo
* @return
* @throws TransactionAbortedException
* @throws DbException
*/
private Iterator<Tuple> getTupleIterator(int pageNo) throws TransactionAbortedException, DbException{
if(pageNo >= 0 && pageNo < file.numPages()) {
HeapPageId pid = new HeapPageId(file.getId(), pageNo);
HeapPage page = (HeapPage) Database.getBufferPool().getPage(tid, pid, Permissions.READ_ONLY);
if(page == null) throw new DbException("get iterator fail! pageNo #" + pageNo + "# is invalid!");
return page.iterator();
}
throw new DbException("get iterator fail!!! pageNo #" + pageNo + "# is invalid!");
}
@Override
public boolean hasNext() throws DbException, TransactionAbortedException {
//需要先判断文件有没有打开
if(it == null) return false;
if(pageNo >= file.numPages()) return false;
if(!it.hasNext() && pageNo == file.numPages() - 1) return false;
return true;
}
@Override
public Tuple next() throws DbException, TransactionAbortedException, NoSuchElementException {
if(it == null) throw new NoSuchElementException("file not open!");
if(!it.hasNext()) {
if(pageNo < file.numPages() - 1) {
pageNo ++;
it = getTupleIterator(pageNo);
return it.next();
}else {
return null;
}
}
return it.next();
}
@Override
public void rewind() throws DbException, TransactionAbortedException {
close();
open();
}
@Override
public void close() {
it = null;
}
}
Exercise6
exercise6注意是做一个全表扫描,主要验证上一个exercise实现的迭代器的正确性,实现SeqScan即可,其中SeqScan给扫描的表支持别名,然后getTupleDesc需要去修改每个字段的名字,加上别名如a.table。实现如下:

四、踩坑记录
1.exercise1中TupleDesc计算所有字段占用的字节数,当时不太理解方法的描述,因为测试用例使用int类型,我简简单单用4*numTuples就过了,后面的erercise的测试用例过不了,仔细结合Type再修改了一下:

2.exercise4中HeapPage获取所有有效字段的迭代器时,没使用bitmap来判断slot是否被占用,导致了测试时空指针。正确的做法是逐个判断slot是否被占用,slot被占用才将tuple加入list中,最后返回list的iterator:

3.exercise6时有个test一直过不了,爆的是数组越界:

一开始以为是迭代器写的有问题,debug无果,后面打日志才发现是前面计算header占用字节数出现的低级错误,337/8=42导致分配的是42bytes的数组,正确的应该用337/8.0再取ceil结果是43:

五、总结
6.830这个实验是在6.824的交流群知道的,当时知道是用Java写的就打算有空来写写,感谢群佬们。做完lab1对数据库数据的组织形式有一定的了解,实验给的讲义也很棒,实验代码的注释也很详细,测试用例也能检测出一些细节上的错误,是个学习数据库知识不错的实验。实验总共花了两个下午一个晚上一个早上来写代码,2个多小时写总结。写完总结这就去做实验2~
实验时间:10.01-10.03
报告撰写时间:10.03 14点到16点
原文链接:https://blog.csdn.net/weixin_45834777/article/details/120595851
所属网站分类: 技术文章 > 博客
作者:飞翔公园
链接:http://www.javaheidong.com/blog/article/296179/a3231ec39feffd766e74/
来源:java黑洞网
任何形式的转载都请注明出处,如有侵权 一经发现 必将追究其法律责任
昵称:
评论内容:(最多支持255个字符)
---无人问津也好,技不如人也罢,你都要试着安静下来,去做自己该做的事,而不是让内心的烦躁、焦虑,坏掉你本来就不多的热情和定力