

Apache Kafka 架构和相关概念
发布于2020-11-20 08:32 阅读(624) 评论(0) 点赞(25) 收藏(2)
Apache Kafka 架构和相关概念
Apache Kafka 是一款开源的分布式消息引擎系统
消息引擎的同类
- ActiveMQ
- RabbitMQ
- WebSphere MQ
- Rocket MQ
- JMS仅仅是一组 API 协议
消息引擎的作用
削峰填谷
缓冲上下游瞬时突发流量,使其更平滑.特别是对于那种发送能力很强的上游系统,如果没有消息引擎的保护,“脆弱”的下游系统可能会直接被压垮导致全链路服务“雪崩”。
但是,一旦有了消息引擎,它能够有效地对抗上游的流量冲击,真正做到将上游的“峰”填满到“谷”中,避免了流量的震荡
解耦
使发送方与接收方松耦合,仅以协议的方式进行通讯,简化了开发.
消息引擎使用方式
点对点
也叫消息队列,每个消息只能被一个下游的消费者消费.
把消息发给多个处理者,方便扩展处理量,同时也意味着,当一个消费者消费了这条消息,这条消息就不存在了.别人无法消费
发布/订阅
把消息广播给每个处理者.
由于每条消息都会传递给每个订阅者,因此无法扩展处理。kafka的consumerGroup同时支持上述这两种方式.
Kafka模型的优势在于,每个主题都具有这两个属性-可以扩展处理范围,并且是多用户的-无需选择其中一个。
KAFKA 拓扑结构图
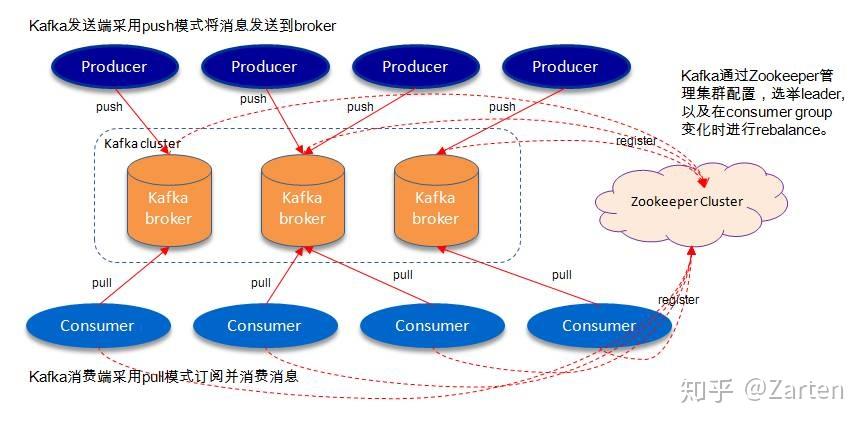
KAFKA 结构图
KAFKA 概念
Broker
Broker 负责接收和处理客户端发送过来的请求,以及对消息进行持久化, 一个 Kafka集群由多个
Broker 组成. 也可以理解为 KAFKA 服务器
Client
分为生产者和消费者
- producer
向主题发布消息的客户端应用程序称为生产者(Producer),生产者程序通常持续不断地向一个或多个主题发送消息.
生产者负责选择将记录分配给主题中相应的分区。可以简单地以轮循方式完成此操作,也可以根据某些语义分区功能(例如基于记录中的某些键)完成此操作。
2. Consumer 订阅这些主题消息的客户端应用程序就被称为消费者(Consumer)
消费者存在于消费者组中,主题的每条记录都会传递到订阅消费者组中的一个消费者实例。使用者实例可以位于单独的进程中,也可以位于单独的机器上。
Topic
发布订阅的对象是主题(Topic),可以是某个业务,某个应用甚至某类数据的逻辑分类.
Partitioning
每个分区都是有序的,不变的记录序列,这些记录连续地追加到结构化的提交日志中.分区中的每个记录均分配有一个称为偏移的顺序ID号,该ID
唯一地标识分区中的记录。
Kafka中的分区机制指的是将每个主题划分成多个分区(Partition),每个分区是一组有序的消息日志。生产者生产的每条消息只会被发送到一个分区中,也就是说如果向一个双分区的主题发送一条消息,这条消息要么在分区
0 中,要么在分区 1 中。
每个主题下可以有多个分区.
分区的作用:
- 提供扩展性, TOPIC 下可以增加分区
- 提供并行性. 方便多个消费都并行处理
Replication
备份的思想很简单,就是把相同的数据拷贝到多台机器上,而这些相同的数据拷贝在 Kafka 中被称为副本(Replica)。
副本的数量是可以配置的,这些副本保存着相同的数据,但却有不同的角色和作用。Kafka 定义了两类副本:领导者副本(Leader Replica)和追随者副本(Follower Replica)。前者对外提供服务,这里的对外指的是与客户端程序进行交互;而后者只是被动地追随领导者副本而已,不能与外界进行交互。
副本的作用:
保证了 KAFKA 容错能力
Producer
生产者:
向主题发布新消息的应用程序。
生产者负责选择将记录分配给主题中的分区。可以简单的以轮循的方式完成,也可以根据某些语义分区(例如基于记录中的某些键)完成此操作。
客户端程序只能与分区的领导者副本进行交互
Consumer
消费者
从主题订阅新消息的应用程序。 消费都必须要在消费组中, Topic
对应的分区平均分配到消费组的中消费实例上.
Consumer Group
消费组
每个consumer属于一个特定的consumer group,可为每个consumer指定group
name,若不指定,则属于默认的group,一条消息可以发送到不同的consumer
group,但一个consumer group中只能有一个consumer能消费这条消息.
消费者与消费组的关系
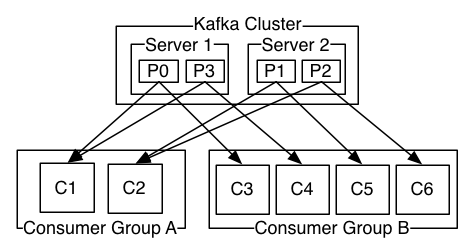
由两台服务器组成的Kafka群集,其中包含四个带有两个使用者组的分区(P0-P3)。消费者组A有两个消费者实例,而组B有四个。
consumer group A中的C1 消费 P0和 P3分区的记录
consumer group A中的C2 消费P1和P2分区的记录
consumer group B有4个消费者,分别对应一个分区
Consumer Rebalance
消费者组里面的所有消费者实例不仅“瓜分”订阅主题的数据,而且更酷的是它们还能彼此协助。假设组内某个实例挂掉了,Kafka 能够自动检测到,然后把这个 Failed 实例之前负责的分区转移给其他活着的消费者。
Offset
在 KAFKA 中,offSet有两种含义
- 分区位移
消息的是分区内的消息位置,这个不变的.即一旦消息被成功写入到一个分区上,它的位移值就是固定的了
- 消费者位移
是随时变化的,是消费者消费进度的指示器。另外每个消费者有着自己的消费者位移.
Kafka与传统消息引擎的对比:
点对点
传统的消息队列模型的特点在于消息一旦被消费,就会从队列中被删除,而且只能被下游的一个
Consumer 消费
发布/订阅
允许消息被多个 Consumer 消费,每个订阅者都必须要订阅主题的所有分区。
Kafka 仅仅使用 Consumer Group 这一种机制,却同时实现了传统消息引擎系统的两大模型:如果所有实例都属于同一个 Group,那么它实现的就是消息队列模型;如果所有实例分别属于不同的 Group,那么它实现的就是发布 / 订阅模型。
理想情况下,Consumer 实例的数量应该等于该 Group 订阅主题的分区总数。
参考
极客时间
极客时间
apache kafka
Kafka架构图
所属网站分类: 技术文章 > 博客
作者:java王侯
链接:http://www.javaheidong.com/blog/article/3371/8fb3ddd4faf9d37d2259/
来源:java黑洞网
任何形式的转载都请注明出处,如有侵权 一经发现 必将追究其法律责任
昵称:
评论内容:(最多支持255个字符)
---无人问津也好,技不如人也罢,你都要试着安静下来,去做自己该做的事,而不是让内心的烦躁、焦虑,坏掉你本来就不多的热情和定力